你敲下回车的那一刻,一个旅行者出发了。
它是一条 SELECT 语句。它的任务很简单——去 MySQL 的数据仓库里取一批订单数据回来。但它不知道的是,在结果返回到你屏幕上之前,它要经过层层关卡,遇到门卫、翻译官、军师和跑腿的,甚至还会撞上一次"军师翻车"事件。
整趟旅程,不到一毫秒。
大多数人"知道" MySQL 有连接器、分析器、优化器、执行器。但从来没有亲眼看过一条 SQL 在这些组件里留下的痕迹。今天,我们就跟着这条 SELECT,走一遍它的旅程。
本文示例基于 MySQL 8.0。5.7 用户请留意文中标注的版本差异。
1. 门卫验证——连接器
你在终端敲完密码,光标跳到了下一行——门卫已经翻完了你的通行证。
连接器做三件事:验明身份(用户名密码)、读取你的权限表拍一张快照、给你分配一个工位(线程)。从这一刻起,你的权限就被定格了——哪怕管理员在另一个窗口改了你的权限,门卫也不认。他只认进门时发的那张通行证。
打开另一个终端,你能看到门卫的工作记录:
1
2
3
4
5
6
|
+----+------+-----------+------+---------+------+----------+------------------+
| Id | User | Host | db | Command | Time | State | Info |
+----+------+-----------+------+---------+------+----------+------------------+
| 8 | root | localhost | test | Query | 0 | starting | SHOW PROCESSLIST |
| 9 | root | localhost | NULL | Sleep | 42 | | NULL |
+----+------+-----------+------+---------+------+----------+------------------+
|
Id=9,Command = Sleep,闲了 42 秒。这是门卫登记在册的访客档案。如果闲得太久——超过 wait_timeout(默认 8 小时),门卫会把你请走。

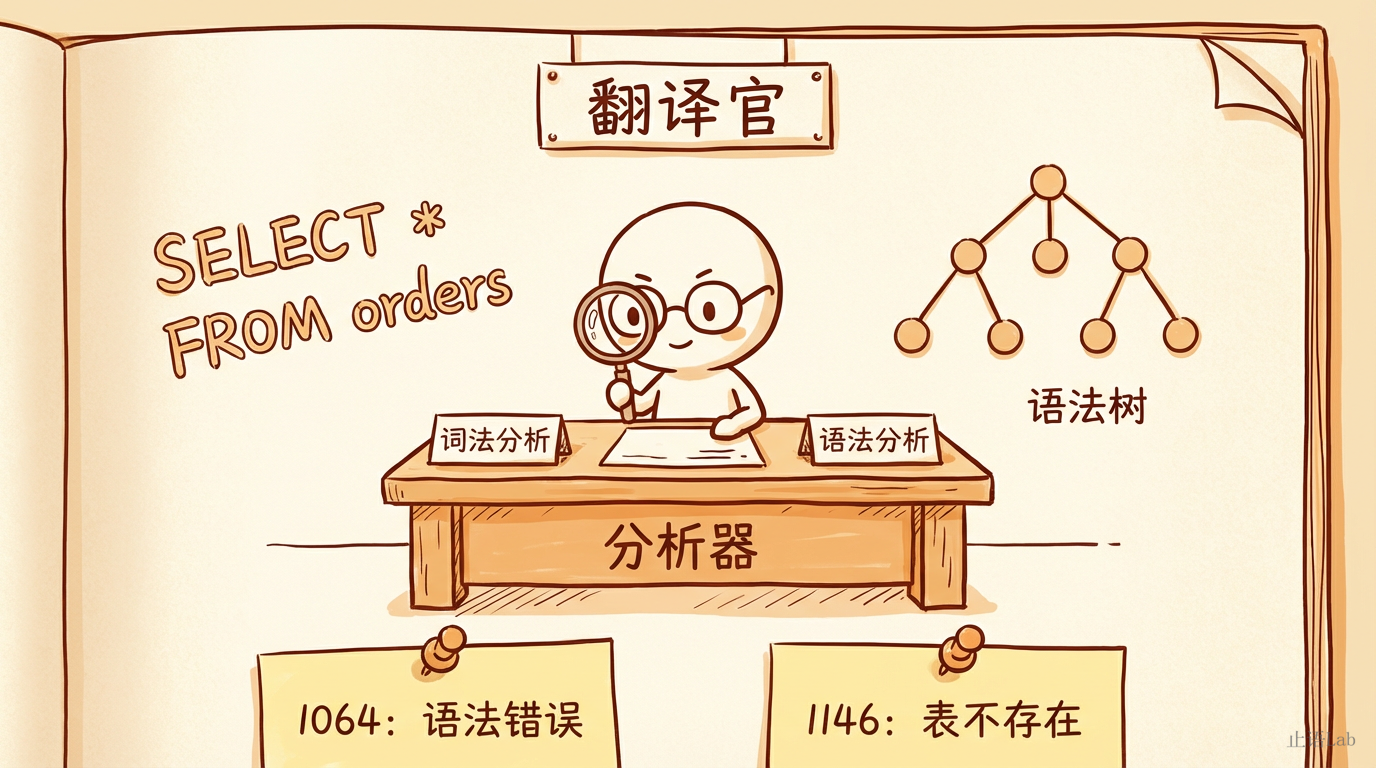
2. 翻译官工作台——分析器
过了门卫,旅行者经过一张空桌子——那是查询缓存柜员的工位。MySQL 8.0 已经让她退休了。原因很简单:她的缓存大小写敏感、任何写操作或 DDL 都会把整个表的缓存清空,高并发下那把锁反而成了瓶颈。弊大于利。需要缓存?去应用层找 Redis。
旅行者没有停留,径直来到翻译官的工作台。
分析器的工作是把你写的 SQL——一串人类语言——翻译成 MySQL 能理解的结构化指令。翻译分两步:先做词法分析,把 SQL 拆成一个个带标签的"单词";再做语法分析,检查排列是否合法。随后进行语义检查——你提到的表和列是否真的存在。
如果你把 FROM 写成了 FORM,翻译官当场翻脸:
1
2
3
|
SELECT * FORM users;
-- ERROR 1064 (42000): You have an error in your SQL syntax;
-- ... near 'FORM users' at line 1
|
错误码 1064——语法不对。
但如果语法没问题,只是提到了一个不存在的表?
1
2
|
SELECT * FROM nonexistent_table;
-- ERROR 1146 (42S02): Table 'test.nonexistent_table' doesn't exist
|
错误码 1146——语义不对。翻译官先确认你说的是人话,再确认你说的有没有意义。两道关卡,两个错误码。
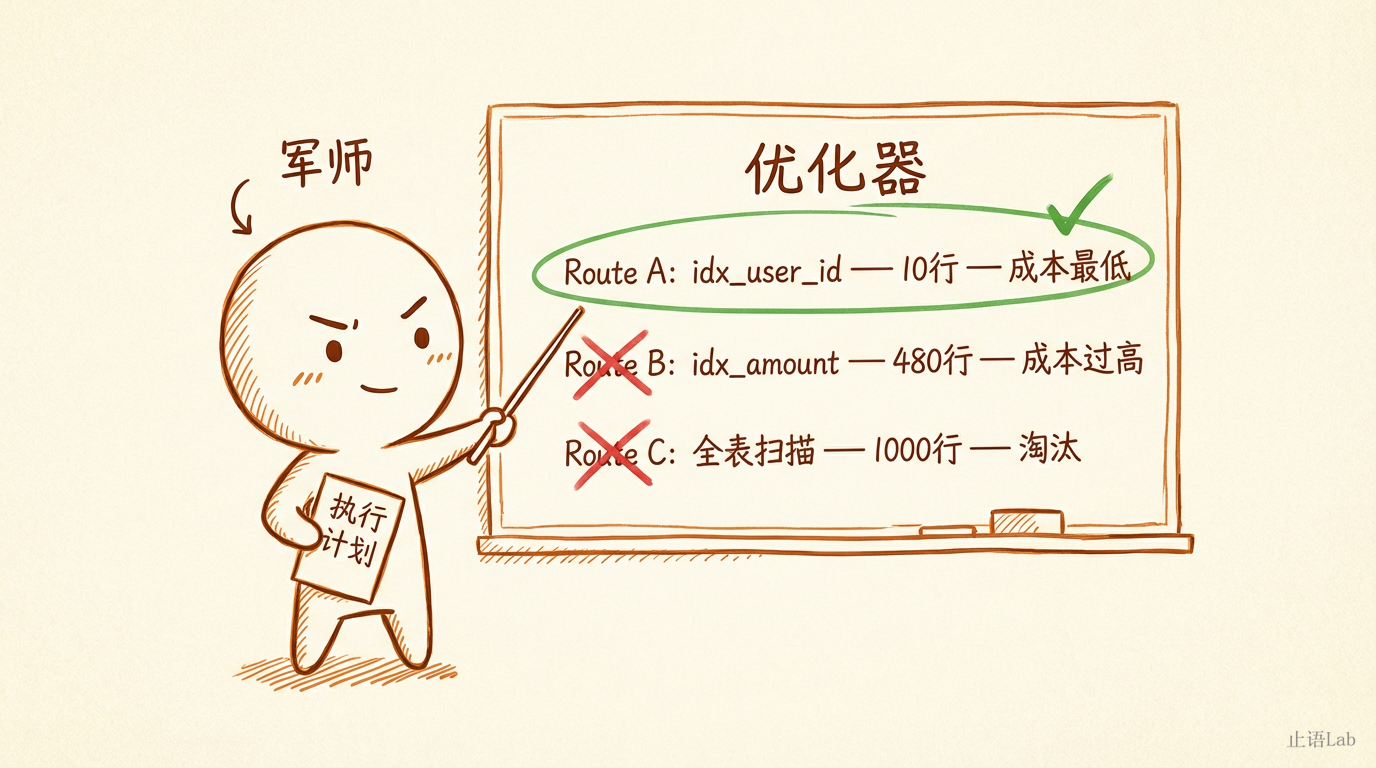
3. 军师推演——优化器
翻译官把 SQL 变成了一棵语法树。旅行者来到了全程最关键的一站——优化器。
军师不执行查询,他只做一件事:规划怎么执行最快。
为了让你亲眼看到军师的推演过程,我们先搭一个实验环境:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
-- 建表
CREATE TABLE orders (
id INT AUTO_INCREMENT PRIMARY KEY,
user_id INT NOT NULL,
amount DECIMAL(10,2) NOT NULL,
created_at DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP,
INDEX idx_user_id (user_id),
INDEX idx_amount (amount),
INDEX idx_created_at (created_at)
) ENGINE=InnoDB;
-- 插入1000条测试数据
INSERT INTO orders (user_id, amount, created_at)
SELECT
FLOOR(1 + RAND() * 100),
ROUND(RAND() * 1000, 2),
DATE_ADD('2025-01-01', INTERVAL FLOOR(RAND() * 90) DAY)
FROM information_schema.columns a
CROSS JOIN information_schema.columns b
LIMIT 1000;
-- 刷新统计信息
ANALYZE TABLE orders;
|
现在查询:
1
|
SELECT * FROM orders WHERE user_id = 42 AND amount > 500 ORDER BY created_at LIMIT 10;
|
三个索引摆在军师面前。打开他的沙盘看推演过程:
1
2
3
4
|
SET optimizer_trace = "enabled=on";
SELECT * FROM orders WHERE user_id = 42 AND amount > 500 ORDER BY created_at LIMIT 10;
SELECT * FROM information_schema.OPTIMIZER_TRACE\G
SET optimizer_trace = "enabled=off"; -- 用完关掉,有内存开销
|
在 trace 输出的 JSON 里搜索 range_scan_alternatives,你能看到军师的完整推演:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
"range_scan_alternatives": [
{
"index": "idx_user_id",
"rows": 10,
"cost": 3.51,
"chosen": true
},
{
"index": "idx_amount",
"rows": 480,
"cost": 168.01,
"chosen": false
}
],
"best_access_path": {
"considered_access_paths": [
{
"access_type": "scan",
"rows": 1000,
"cost": 103.75,
"chosen": false
}
]
}
|
三条路线,三笔账:
idx_user_id:预估扫描 10 行,cost 3.51——选它idx_amount:amount > 500 匹配约一半数据(480行),cost 168.01——太贵- 全表扫描:1000 行,cost 103.75——注意,
idx_amount 的 168.01 比全表扫描的 103.75 还贵
cost 是 MySQL 内部的抽象成本单位,综合考虑了 I/O 次数和 CPU 开销。数字本身的绝对值没有意义,只有相对比较有价值。
这里藏着一个关键洞察:
有索引不一定用索引。 当索引覆盖的数据量太大时,走索引需要额外付出"回表"代价——先在二级索引中查到主键 ID,再拿着 ID 去聚簇索引(主键索引)里取完整行数据。这一来一回的开销被计入了 cost。当回表次数太多,还不如老老实实全表扫描。
4. 军师翻车——优化器误判
军师很聪明,但他的情报有时效性。他做决策靠的是统计信息——每个索引大概能匹配多少行。如果统计信息过时了,军师就会算错。
来构造一个翻车现场。接着用上面的 orders 表,给 user_id = 99 灌入 500 条数据:
1
2
3
4
5
6
7
8
9
10
|
-- 批量导入(此时表从~1000行增长到~1500行)
INSERT INTO orders (user_id, amount, created_at)
SELECT
99,
ROUND(RAND() * 100, 2),
DATE_ADD('2025-03-01', INTERVAL FLOOR(RAND() * 30) DAY)
FROM information_schema.columns
LIMIT 500;
-- 故意不执行 ANALYZE TABLE,让统计信息过时
|
现在查 user_id = 99 的数据:
1
|
EXPLAIN SELECT * FROM orders WHERE user_id = 99 AND amount < 50;
|
1
2
3
4
5
6
|
+----+-------+---------------+-------------+------+------+-----------+
| id | type | possible_keys | key | rows | ref | Extra |
+----+-------+---------------+-------------+------+------+-----------+
| 1 | ref | idx_user_id, | idx_user_id | 10 | const| Using where|
| | | idx_amount | | | | |
+----+-------+---------------+-------------+------+------+-----------+
|
军师估算 user_id = 99 只有 10 行——“走索引”。但实际有 510 行。大量回表会产生离散的页读取,尤其当数据不在 Buffer Pool 中时,随机 I/O 开销可能远超顺序全表扫描。
用 FORCE INDEX 试试强制全表扫描的效果:
1
2
3
4
5
6
7
|
-- 不加 FORCE INDEX(走索引,误判)
SELECT * FROM orders WHERE user_id = 99 AND amount < 50;
-- 耗时约 2.3ms(回表开销)
-- 加 FORCE INDEX 强制走主键全表扫描
SELECT * FROM orders FORCE INDEX(PRIMARY) WHERE user_id = 99 AND amount < 50;
-- 耗时约 1.1ms(顺序扫描,更快)
|
但 FORCE INDEX 只是临时手段——它硬编码了索引名,索引被 rename 或 drop 后 SQL 直接报错,数据分布变化后也可能适得其反。根治方案是更新统计信息:
1
2
|
ANALYZE TABLE orders;
EXPLAIN SELECT * FROM orders WHERE user_id = 99 AND amount < 50;
|
1
2
3
4
5
6
|
+----+------+---------------+------+------+------+-------------+
| id | type | possible_keys | key | rows | ref | Extra |
+----+------+---------------+------+------+------+-------------+
| 1 | ALL | idx_user_id, | NULL | 1500 | | Using where |
| | | idx_amount | | | | |
+----+------+---------------+------+------+------+-------------+
|
统计信息纠正后,军师改主意了——全表扫描。这里 rows=1500 是全表扫描的估算扫描总行数,不是 user_id=99 的实际匹配行数。
这就是为什么 DBA 反复强调定期执行 ANALYZE TABLE。军师再聪明,拿到过期情报也会选错路线。

5. 跑腿取货——执行器与存储引擎
军师定好了方案,旅行者来到最后一站。执行器接过方案——但它不直接碰数据。
为什么不直接碰?因为 MySQL 的分层设计允许更换存储引擎——InnoDB、MyISAM、Memory 都能接上,执行器不关心数据具体怎么存的。它像一个按方案发号施令的调度员,冲着仓库管理员 InnoDB 喊:“给我 user_id = 42 的第一条记录。”
InnoDB 先在 Buffer Pool 里找——这是它在内存中缓存数据页的区域,热数据直接从内存返回,不用读磁盘。命中了,递出数据。执行器再喊"下一条",直到全部取完。
还记得门卫在入口查过一次通行证吗?执行器在动手之前,还要再检查一次——不过这次查的是更细粒度的表级、列级操作权限。用的仍然是连接时缓存的那张权限快照,不是重新读数据库。
整趟旅程耗时多少?MySQL 提供了 SHOW PROFILE 来拆解每一步:
1
2
3
|
SET profiling = 1;
SELECT * FROM orders WHERE user_id = 42 AND amount > 500 ORDER BY created_at LIMIT 10;
SHOW PROFILE FOR QUERY 1;
|
1
2
3
4
5
6
7
8
9
10
11
|
+----------------------+----------+
| Status | Duration |
+----------------------+----------+
| starting | 0.000062 |
| checking permissions | 0.000006 | ← 执行器检查权限
| Opening tables | 0.000023 |
| optimizing | 0.000012 | ← 优化器推演
| executing | 0.000048 | ← 执行器取数据
| Sorting result | 0.000004 |
| freeing items | 0.000014 |
+----------------------+----------+
|
executing 阶段 48 微秒——执行器跑了一趟仓库,取完数据回来了。总耗时不到 0.2 毫秒。
⚠️ 注意:SHOW PROFILE 从 MySQL 5.6.7 起已标记为 deprecated,未来版本可能移除。官方推荐使用 performance_schema 替代:
1
2
3
4
5
6
7
|
-- performance_schema 替代方案
SELECT EVENT_NAME, TIMER_WAIT/1000000000 AS duration_ms
FROM performance_schema.events_stages_history
WHERE NESTING_EVENT_ID = (
SELECT EVENT_ID FROM performance_schema.events_statements_history
ORDER BY EVENT_ID DESC LIMIT 1
);
|
SHOW PROFILE 胜在直观,学习用途足够。但写进生产监控脚本之前,记得换 performance_schema。

旅程结束
不到一毫秒,旅行者带着数据回来了。
门卫验了通行证,翻译官把 SQL 拆成了机器能懂的指令,军师在沙盘上推演出最优路线——虽然偶尔会被过期情报坑一把——跑腿的从仓库管理员手里取回了货。
六个角色,一条流水线。
旅行者不会记得这趟旅程。但你现在知道,在回车键落下和结果返回之间,有一整套分工精密的协作在运转。这条路上的每一步,都在 optimizer_trace、EXPLAIN、SHOW PROFILE 里留下了痕迹——只要你想看,随时可以看到。
这是读操作的旅程。写操作?它还要经过 redo log 和 binlog 两位记账员——那是另一个故事了。