
导读:反射的"难用"不是 Go 团队的设计失误,而是与错误处理、迟到的泛型一脉相承的系统性选择。从 interface{} 拆箱机制讲起,用实测数据量化代价,追踪标准库的 24 个包为何离不开它,最后给你一棵可操作的决策树。
你第一次写 reflect.ValueOf 的时候,心里什么感觉?
我猜大概率是"这也太绕了"——明明知道这个 struct 有个 Name 字段,却要先 ValueOf、再 Elem、再 FieldByName,最后还得 SetString。一行 u.Name = "Alice" 能搞定的事,反射要写五行。
更要命的是,写错了编译器不会提醒你。它会在运行时给你一个 panic,栈信息指向 reflect 包深处某个你看不懂的函数。
我在项目里踩过三类坑。
有一次我写了个通用的 struct 字段复制函数,用 FieldByName 按名字匹配。上线后发现,传进来的值偶尔是指针的指针,Elem() 少调一次就 panic。排查了两个小时,因为错误信息只有一句 reflect: call of reflect.Value.FieldByName on ptr Value——它不会告诉你哪个字段、哪一层出的问题。
更隐蔽的是性能。我在一个内部 RPC 框架里用反射做参数绑定,用 pprof 一看,近三分之一的 CPU 时间花在 reflect.Value.call 上。换成接口 + 类型断言后,CPU 占用降回了正常水平。
最让人后悔的是维护。半年后同事接手那段反射代码,问我:“这里为什么要 Kind() == reflect.Ptr 判断两次?“我自己看了半天也想不起来了。
踩过的人都有共鸣。但大多数人的结论停留在"反射难用,少用”。
我想说的是另一件事:Go 反射的"难用”,大概率不是设计能力不足,而是一种系统性的设计选择。
1. 反射不是魔法,是拆箱
要理解为什么反射"难用",先得知道它到底在干什么。
很多人把反射想象成某种高深的运行时黑魔法。其实不是。反射的全部秘密藏在一个你每天都在用的东西里——interface{}。
Go 里任何值赋给 interface{} 的时候,会被自动打包成一对指针:(类型指针, 数据指针)。如果你好奇底层长什么样,可以用 unsafe 窥探一下(以下是简化的近似模拟,不是 runtime 的精确定义):
|
|
[实测 Go 1.26.2] interface{} 就是 16 个字节,两个指针,没有更多了。
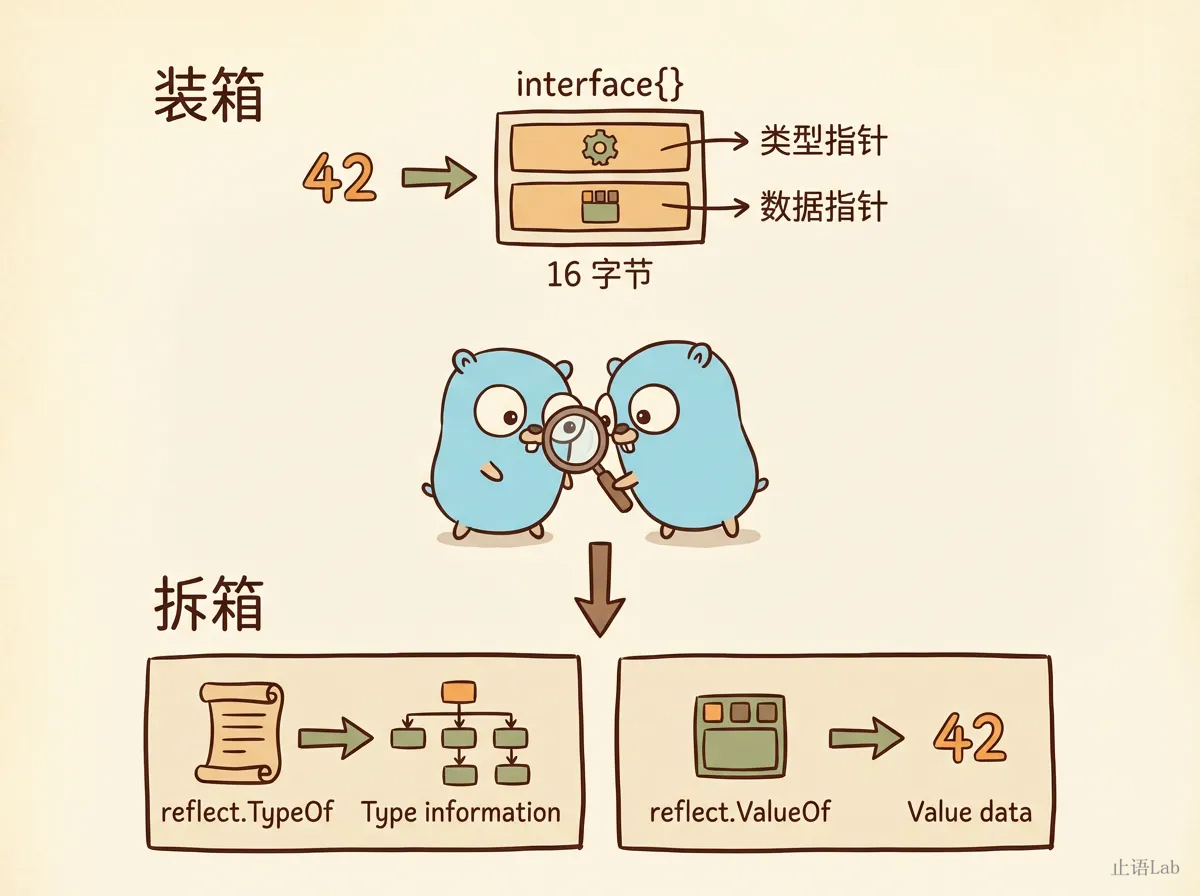
而 reflect.TypeOf 和 reflect.ValueOf 做的事,就是把这对指针拆开来看:
|
|
你传给反射的东西,在传入的那一刻就已经被打包了。反射只是帮你把包装纸撕开,看看里面装的是什么类型、什么值。
这也解释了为什么 reflect.TypeOf 开销极低——底层主要是读取已有的类型指针信息。我的 benchmark 数据证实了这一点:
| 操作 | 耗时 | 说明 |
|---|---|---|
| reflect.TypeOf | 0.26 ns | 读取类型指针信息,几乎免费 |
| reflect.ValueOf | 0.26 ns | 包装为 Value,几乎免费 |
[实测 Go 1.26.2, Apple M4 Pro]
反射的开销不在"获取类型信息"这一步。那开销在哪?
2. 真正的代价:按名字查找 + 动态分发
反射真正贵的地方,是你开始"用"它的时候。
看这组 benchmark 数据:
| 操作 | 耗时 (ns/op) | 堆分配 | vs 直接操作 |
|---|---|---|---|
| 直接赋值 3 个字段 | 0.25 | 0 | 1x |
| 反射赋值(FieldByName) | 85 | 0 | 340x |
| 反射赋值(缓存 Index) | 10.4 | 0 | 42x |
| 直接方法调用 | 0.25 | 0 | 1x |
| 反射方法调用 | 192 | 96B / 3次 | 768x |
| 接口方法调用 | 0.26 | 0 | ~1x |
[实测 Go 1.26.2, Apple M4 Pro, go test -bench=. -benchmem -count=3]
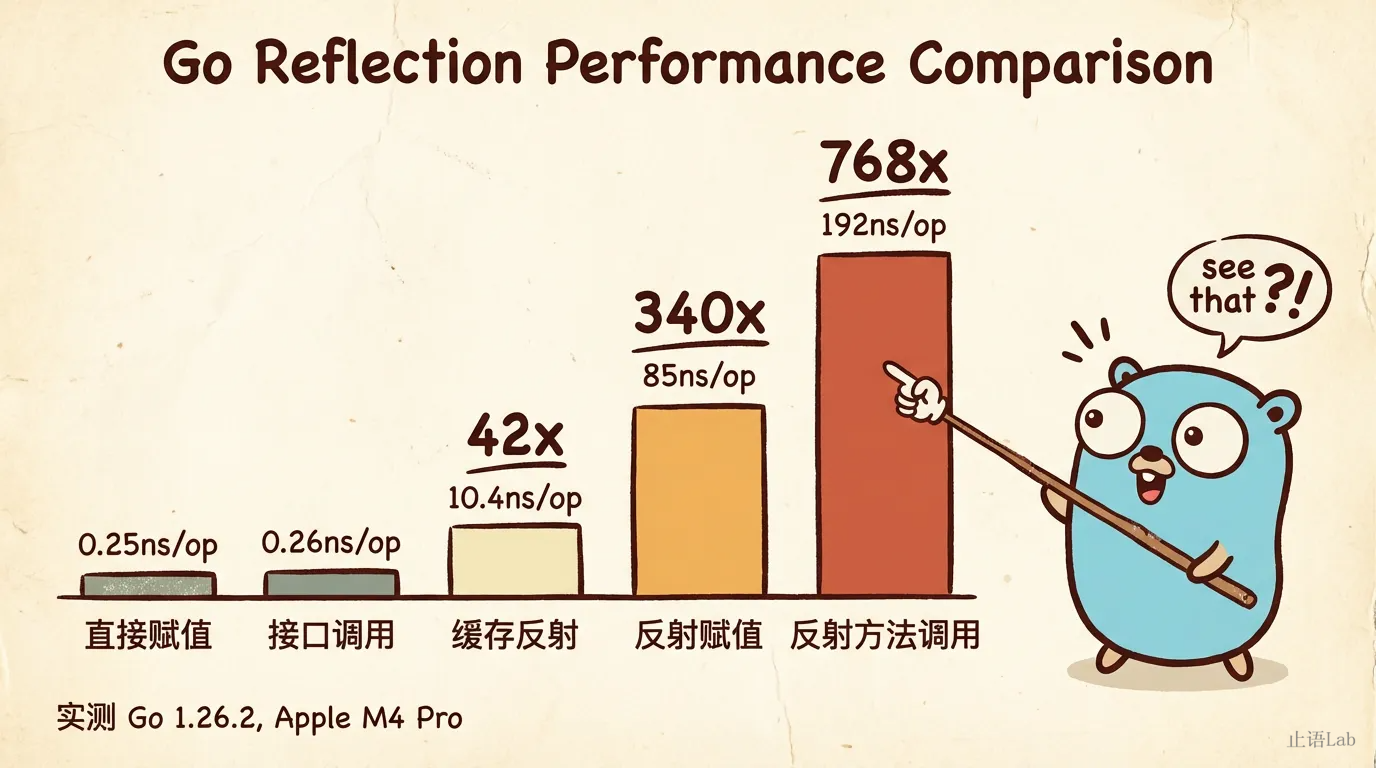
FieldByName 是性能杀手。 它要在 struct 的字段列表里按名字查找匹配,每次调用都要比较字符串。85ns 看着不多,但在未做缓存的场景下,一个 10 字段的 struct 遍历一遍就是 850ns。当然,成熟的库(如 encoding/json)会在首次解析后缓存字段信息,不会每次都走 FieldByName。这里展示的是未缓存场景下的裸性能,让你对它的开销有个直观认识。
缓存能帮忙,但有限。把 FieldByName 的结果缓存为 Index,查找时间从 85ns 降到 10ns,快了 8 倍,但仍然是直接赋值的 42 倍。
反射方法调用更重——768 倍于直接调用,还有堆分配。每次 Call 要把参数包装成 []reflect.Value,这意味着 GC 压力。而接口方法调用和直接调用性能几乎一样(0.26ns vs 0.25ns)。很多场景下,你根本不需要反射,用接口 + 类型断言就够了。
3. 逃生舱门:标准库离不开反射
反射慢、危险、难读。但标准库自己大量使用它。
我统计了 Go 1.26.2 标准库源码(非测试文件):24 个公共包直接 import 了 "reflect",涉及 156 个源码文件。
其中引用最密集的:
| 包 | 引用文件数 | 典型场景 |
|---|---|---|
| encoding/json (v1+v2) | 15 | 运行时不知道你传的 struct 长什么样 |
| encoding/gob | 9 | 二进制编解码,处理任意类型 |
| net/http | 5 | 内部类型适配和处理 |
| text/template | 3 | 模板变量求值 |
| database/sql | 2 | Scan 结果映射到任意 struct |
| fmt | 2 | 打印编译时未知类型的值 |
[实测 Go 1.26.2, grep -rl '"reflect"' $(go env GOROOT)/src/ 统计后按包去重]
它们的共同点:都需要在运行时处理编译时未知的类型。
encoding/json 不知道你会传 User 还是 Order。fmt.Println 不知道你会打印什么类型。这就是反射存在的理由——它是 Go 类型系统的逃生舱门。正常情况下,Go 在编译时就确定了一切。但总有一些场景,编译时真的无法确定类型,反射就是为这些场景准备的后路。
但"有后路"和"后路好走"是两回事。

4. “难用"是故意的:摩擦力设计
回想一下开头的踩坑经历。panic、性能陷阱、维护噩梦——这些痛苦,恰恰是 Go 的设计在起作用。
关键问题来了:反射是必要的,为什么不把 API 设计得好用一点?
看看其他语言怎么做的。Java 有注解(@JsonProperty),有动态代理,可以通过 Constructor.newInstance() 反射创建任意对象,Spring 整个框架建立在反射之上。Java 反射之所以"好用”,是因为 JVM 保留了完整的类型元数据,运行时信息丰富。Python 更直接——getattr(obj, 'name') 一行搞定,__dict__ 直接访问所有属性。作为动态类型语言,Python 的运行时本身就支持内省。
Go 呢?没有注解,没有动态代理。反射创建类型的能力很有限——只能通过 reflect.StructOf 等创建匿名复合类型,不能创建命名类型。想给 struct 加元信息?只能用 struct tag(字符串,编译器不检查格式)。想调用一个方法?先 ValueOf、再 MethodByName、再 Call,参数还得包装成 []reflect.Value。Go 编译为原生二进制,类型信息在编译后大量丢弃——这是设计差异的根因。
Java 的反射像自助餐——随便拿。Go 的反射像处方药——有效,但开方流程故意设计得麻烦。这不是说 Java 或 Python 的设计更差,是设计哲学不同。
而且这种"故意不提供便利"不只体现在反射上。Go 没有异常机制,你必须显式检查每一个 error。直到 1.18 才加入泛型,此前宁可让你写重复代码也不提供参数化类型。没有继承,只有组合。连三元运算符都没有。每一个"不提供"的背后,都是同一个设计哲学:编译时能做的事不留到运行时,能让代码更显式就不提供隐式的捷径。
反射 API 的繁琐是这个系统性选择的一部分。如果你觉得写反射代码很痛苦,那说明摩擦力在正确地工作——它在提醒你:也许不应该在这里用反射。
Go 官方 reflect 包的文档开头写着:
Package reflect implements run-time reflection, allowing a program to manipulate objects with arbitrary types.
“arbitrary types”——任意类型。反射是给 json、sql 这类需要处理"任意类型"的基础设施准备的,不是给业务代码准备的。
这就是我说的"摩擦力设计"——Go 通过让反射 API 足够繁琐,产生自然的摩擦力,让开发者自觉地倾向于更简单的方案。

5. 你什么时候该按逃生舱门?
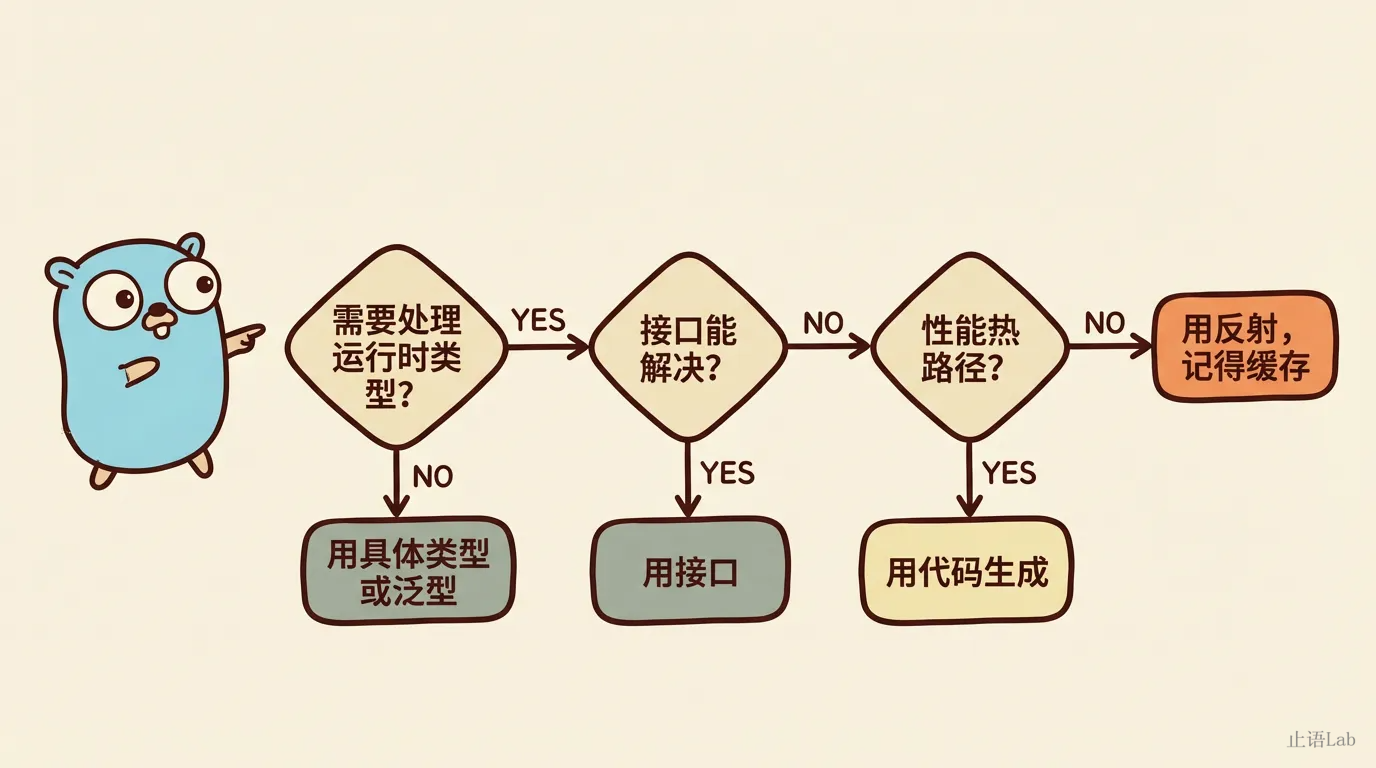
理解了"反射是逃生舱门",实操中怎么判断该不该用?
先问自己:编译时能确定类型吗?能的话,用泛型(Go 1.18+)或具体类型,不需要反射。
如果不能,再看:能用接口 + 类型断言解决吗?接口调用几乎零开销(实测 0.26ns ≈ 直接调用)。大多数"需要反射"的场景,其实定义一个接口就够了。
接口也搞不定——比如需要遍历未知 struct 的所有字段?那还得看:在性能热路径上吗?是的话,用代码生成(go generate)。easyjson、protobuf 都走这条路。不在热路径上,可以用反射,但记住缓存 FieldIndex,别在循环里裸调 FieldByName。
如果写反射代码时你觉得很痛苦,那很可能不是你的问题——是摩擦力在正确地提醒你。
回到开头我踩的那三个坑:
panic 那次,后来为每种需要复制的类型组合定义了明确的转换函数,加上泛型约束,编译时就能拦住类型不匹配。
性能那次,RPC 参数绑定改成了接口 + 类型注册表,每个请求类型实现一个 Bind([]byte) error 接口,框架不需要反射就能调用。
维护那次,没有好的替代方案(确实需要在运行时处理未知类型),但加了缓存:把 FieldByName 的结果缓存到 sync.Map 里,查找耗时从 85ns 降到 10ns。
实际工程中,重构远没有这么干净。但方向是对的。
Go 的反射不是设计得不好。它和 Go 的错误处理、迟到的泛型、没有继承一样,都是同一套设计哲学的产物:宁可让你多写几行代码,也不让你在运行时踩进隐式的坑。
下次你想用 reflect.ValueOf 的时候,先感受一下那股阻力。如果觉得痛苦,说明 Go 的设计正在保护你。