1. 你以为逃逸的开关在代码里?
你写了一个函数,传了个指针,编译器告诉你 moved to heap。你的第一反应是什么?
改代码。换成值接收者,去掉取地址,把 slice 换成数组。
这个直觉对了一半。改写法确实能减少逃逸,但它回答的是"什么写法会逃逸",不是"编译器为什么在这个位置做了保守判断"。翻遍逃逸分析教程,答案都在教你改写法。少有人问:编译器凭什么判断这个变量要逃逸?
Go 官方 FAQ 说:“从正确性角度,你不需要知道变量是分配在栈上还是堆上。“这话没错。但 FAQ 紧接着承认:“存储位置确实对编写高效程序有影响。“正确性你不需要知道,效率你需要知道。
逃逸分析不是逐行扫描你的代码然后判刑。它是编译器在特定上下文中做出的决策——上下文越完整,决策越精确。而影响上下文完整性的关键因素之一,是内联。
函数被内联了,函数边界消失,逃逸分析能看到完整的调用链,做出更精确的判断。函数没被内联,编译器在函数边界处做分析——某些场景下信息不足,只能保守决策。但这里有个重要的"之一”:内联不是唯一的因素,也不是万能的。接口装箱、闭包捕获、反射调用,这些场景内联帮不了。内联是杠杆,不是开关。
你以为逃逸只跟你的写法有关。实际上,编译器能看到多少上下文,至少同等重要。
2. 一个实验看懂内联的真实影响
写一个最简单的函数:
|
|
用 go build -gcflags '-m' 看编译器输出:
|
|
关掉内联,用 go build -gcflags '-l -m':
|
|
两种模式下,参数都不逃逸——a does not escape。这是预期内的:int 按值拷贝传递,编译器不需要做逃逸判断。
真正有意思的是 benchmark(Go 1.26, arm64,我实测):
|
|
0.23 vs 0.70,3 倍差距。堆分配次数都是 0——差异全在函数调用开销上。栈帧分配、参数拷贝、返回值传递,这些固定成本被内联省掉了。
再对照一个基准:直接在 benchmark 里做加法,不走函数调用,0.23 ns/op。和内联版本一模一样。内联生效后,add(i, i) 和 i + i 没有区别。
那更复杂的函数呢?我同时测了一个 doubleVal(接收 *int,解引用后翻倍返回):
|
|
差异消失了。doubleVal 的内部逻辑比 add 复杂,内联省掉的调用开销在总耗时里占比太小。函数越简单,内联收益越大。
那逃逸呢?我特意测了指针参数:func addOne(n *int) int { *n++; return *n }。结果出人意料——无论内联开不开,n does not escape。Go 1.26 的逃逸分析足够智能,即使不内联,也能判断这个指针只被读取、不会逃出函数。
这才是诚实的结论:在大多数简单场景下,现代 Go 的逃逸分析已经足够智能,内联对逃逸结果的影响没有传统教程说的那么大。内联的真正价值是消除函数调用开销,其次才是给逃逸分析提供更多上下文。
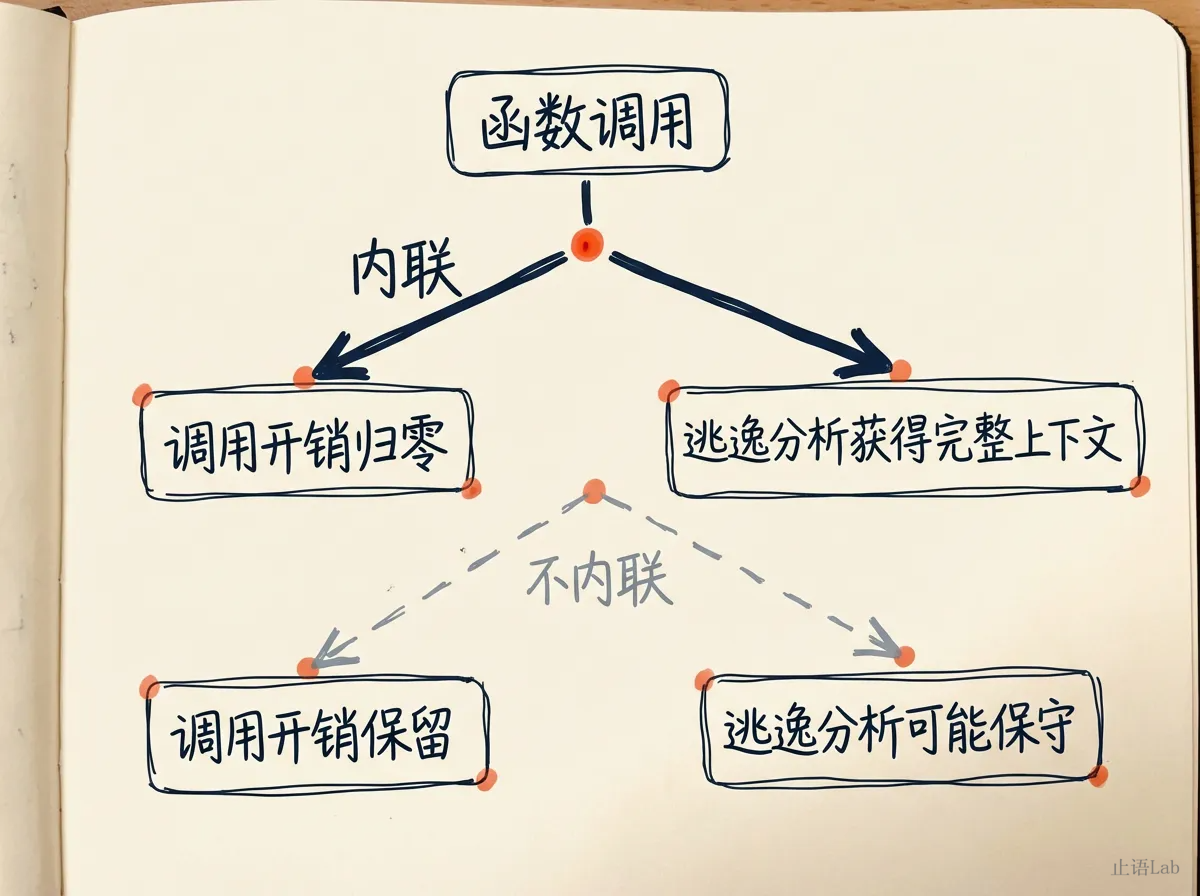
那什么时候内联会影响逃逸结果?当你有复杂的调用链,指针在多层函数间传递时——内联让编译器追踪到指针的完整路径,避免了中间层的保守逃逸。简单的一层调用,编译器自己就能搞定。
3. 编译器的优化管道
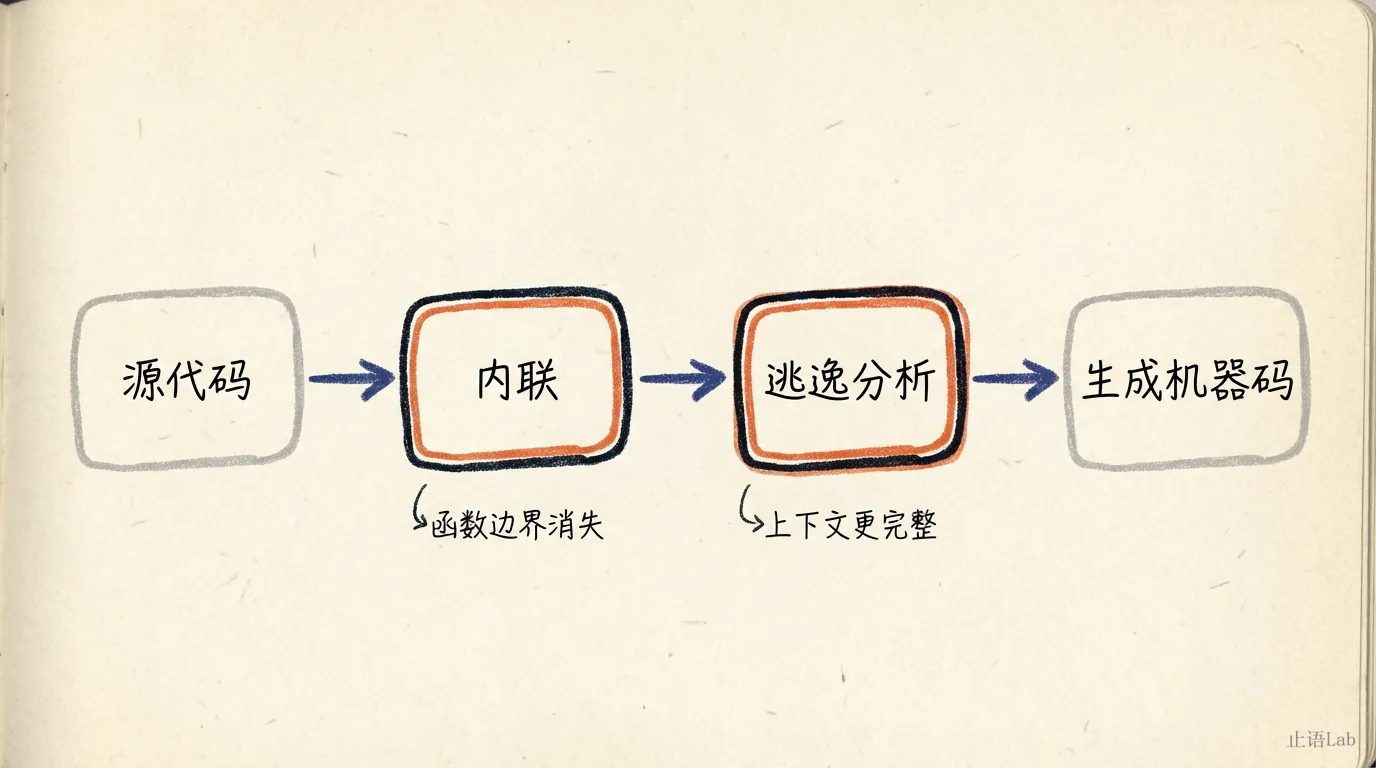
内联和逃逸分析不是独立运行的。Go 编译器的优化管道中,内联在逃逸分析之前:
|
|
内联先执行,把简单函数展开到调用处。逃逸分析紧接着运行,此时一部分函数边界已经消失。这意味着逃逸分析看到的代码比源码更"扁平”,能追踪到更长的调用链。
这个顺序是理解内联与逃逸耦合的关键。但我必须诚实说:Go 编译器的管道比这复杂得多,上面是简化版。实际还有类型检查、SSA 构建、多轮优化等步骤。上面的管道抓住了重点,但不是全貌。
内联预算是关键约束。编译器给每个函数算一个"内联成本”,超过预算就不内联。用 -gcflags '-m -m' 可以看到成本(我实测,Go 1.26):
|
|
成本 22 和 30,低于预算 80,被内联。成本 229,远超预算,不内联。超过预算,编译器放弃内联,逃逸分析就只能看到函数边界。
你的代码越复杂,内联成本越高,超过预算就不内联。这就是为什么"写清晰的代码"不只是风格建议——它直接影响编译器的优化能力。但反过来,不要为了内联而过度拆分函数——可读性也是成本。
4. 下次看到 moved to heap,先别急
看到 moved to heap,别急着改代码。先问两个问题:这个函数被内联了吗?这个逃逸真的影响性能吗?
检查内联状态:
|
|
输出里有 can inline 和 inlining call to,说明被内联了。没有,说明没被内联。
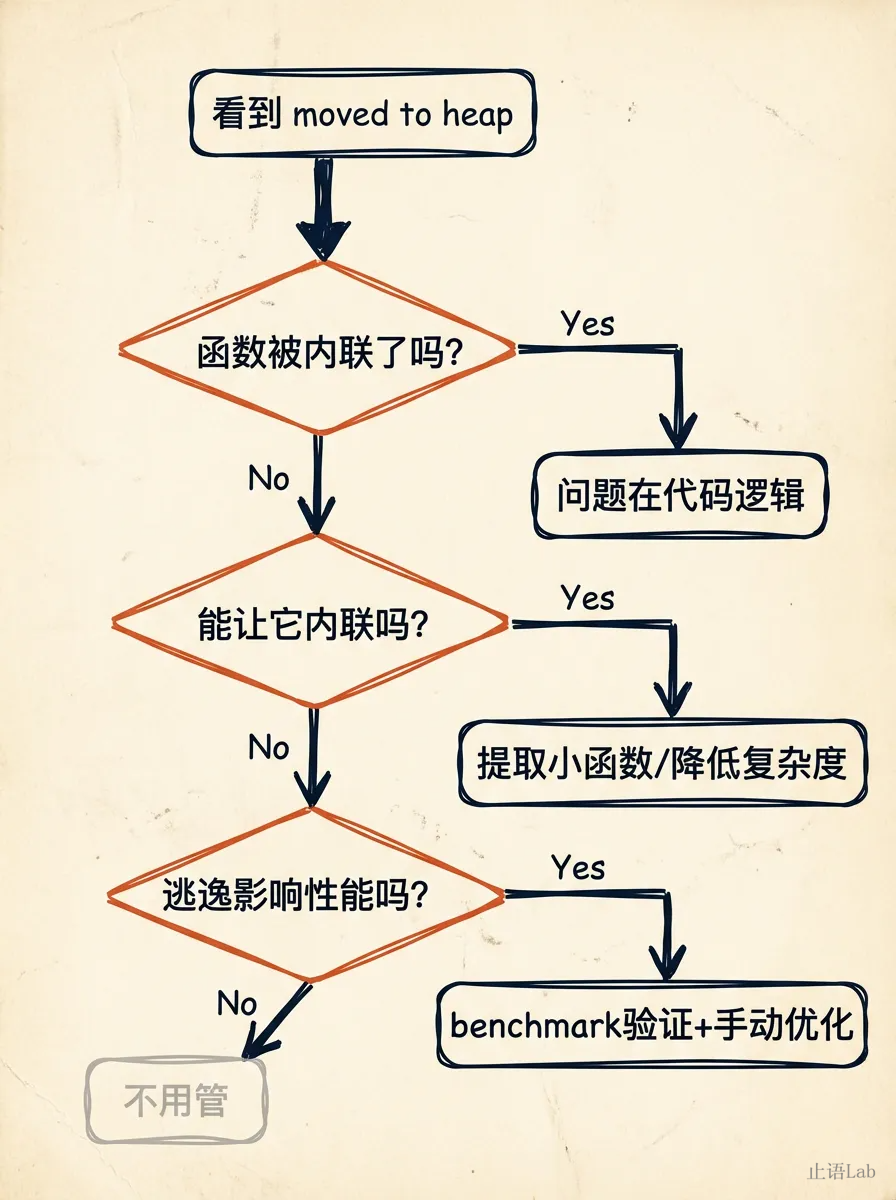
决策路径:
- 函数被内联了 → 逃逸是代码逻辑导致的,该改代码改代码。
- 没被内联 → 先看能不能让编译器内联。提取小函数、降低复杂度、减少内联成本。
- 还是不能内联 → 评估这个逃逸是否真的影响性能。写个 benchmark 跑一下。
- 不影响 → 不管它。内联了仍然逃逸的情况也存在——有些逃逸是代码逻辑决定的,跟内联无关。
最常见的操作是第 2 步:提取小函数。一个 50 行的函数做了三件事,内联成本超标,整函数不被内联。把它拆成三个 15 行的函数,每个成本在预算内,编译器逐个内联。
但不是所有逃逸都需要修。Go 官方说"从正确性角度不需要知道"不是敷衍——如果你的热点路径不在 GC 上,花时间修逃逸就是过度优化。先 profile,确认 GC 是瓶颈,再决定要不要动。大多数服务端的性能瓶颈在网络 IO 和数据库查询上,不是几个堆分配。
内联是逃逸分析的隐藏杠杆——它不是唯一的因素,但理解了它,你就从"我写了什么导致逃逸"升级到"编译器为什么看不到完整上下文”。下次看到 moved to heap,先别急着改代码——先看看编译器看到了多少。