
Go 社区吵了十年的错误处理问题,吵偏了方向。
每隔几个月就有人提新提案,想给 if err != nil 加语法糖。try-catch、check-handler、? 操作符……提案来来去去,Go 团队的态度始终一致:不加。2025 年 6 月,Go 官方博客发了一篇文章,标题很直白——“On No Syntactic Support for Error Handling”,正式关闭了语法变更的大门。
理由很清晰:冗长但可行。写代码、读代码、调试代码是三种不同的活动,Go 当前的显式错误返回在"读"和"调"上表现优秀,代价是"写"的时候多敲几个字。
我怎么看?官方说得对,但只对了一半。冗长不是问题,真正的问题是,绝大多数 Go 项目根本没有错误分层。底层 infra 错误裸奔到 HTTP 响应,业务错误和系统错误混为一谈,panic 被当成快捷 throw。语法糖加不加,跟这些问题毫无关系。
你写了一万遍 if err != nil,但你有没有想过:这个错误该往哪层抛?该对谁暴露?该返回什么 HTTP 状态码?
如果没有想过,那冗长就是最小的毛病。
这篇文章从问题诊断开始,先拆解社区十年争论为什么吵偏了,再用一个真实的信息泄露实验展示无分层的代价。然后给出三层错误分层方案——Infra、Service、Handler 各司其职。接着聊 panic 的边界:什么时候该用,什么时候是滥用。最后用 Go 1.13 以来的标准库新武器串联全局,给出一条不用重写的渐进式改造路径。
1 吵偏了十年

把过去十年 Go 社区关于错误处理的讨论做个分类,大致分三派:
- 语法派:
if err != nil太冗长,需要语法糖 - 语义派:错误需要更好的包装和检查能力(
errors.Is/errors.As) - 架构派:错误需要分层,不同层的错误有不同的处理策略
三派中,语法派声量最大,提案最多,成果为零。语义派的成绩单是 Go 1.13 的错误包装机制和 1.20 的 errors.Join,实打实的语言改进。架构派的讨论散落在各个项目的实践中,没有形成社区级的共识和统一方案。
但架构派才是真正解决问题的方向。
为什么语法派注定失败?因为他们的前提就错了。假设语法是瓶颈,那加语法糖就能解决问题。但实际情况是:即便给你一个 ? 操作符,自动把 error 往上冒泡,你依然面临同样的问题。这个 error 冒泡到哪一层?冒泡上去之后,该返回 400 还是 500?该暴露什么信息给调用方?
语法糖只是让你少打几个字,它解决不了错误该往哪放的问题。就像一栋楼没有消防通道,你把楼梯加宽了也没用。问题不在楼梯宽度,在于根本没规划逃生路线。
Go 官方关闭语法提案这件事本身就说明了一个事实:Go 团队认为当前语法框架足以支撑正确的错误处理实践。他们没有说"现有方式完美",他们说的是"语法层面不需要改动,工程实践层面需要改进"。
一个类比:网络分层。TCP 不会把物理层的信号错误暴露给应用层。物理层错误在物理层处理,链路层错误在链路层处理,每一层只向上暴露对上一层有意义的抽象。如果网卡丢包了,你的 HTTP 客户端看到的是"连接超时",不是"eth0: RX descriptor error, status=0x8"。
Go 项目的错误处理应该遵循同样的原则。但现实是,大部分项目根本没有这样做。包装不等于分层。%w 只是把错误链连起来了,但你依然把底层的 pq: 前缀和 SQL 语句一路透传到了 HTTP 响应。包装是手段,分层是策略。有手段没策略,跟没有手段没区别。
那没有分层的代码,实际跑起来会怎样?
2 无分层的灾难
先看一段常见的 Go 代码。很多人写过,很多人还在写:
|
|
看起来没问题?当数据库正常时确实没问题。但当连接池耗尽、查询超时、表不存在的时候,err.Error() 会返回什么?
我跑了一个实验。用 lib/pq 驱动连接 PostgreSQL,模拟连接池耗尽的场景,直接把 db.Query 返回的错误写到 HTTP 响应里:
|
|
这只是一种场景。将不同错误类型的 err.Error() 汇总起来,你的代码可以泄露以下信息:
- 连接池耗尽:
pq:前缀暴露数据库驱动类型 - 查询失败:
SQLSTATE暴露错误分类 - 权限不足:
database字段暴露数据库名 - SQL 语法错误:
query暴露完整 SQL 语句 - 表不存在:
table暴露表名
五种场景,五类泄露。每一种单独看"只是一条错误信息",但攻击者可以通过触发不同错误来拼出你的后端架构。
有人说:“我用 fmt.Errorf 包一层不就好了?”
|
|
试试看。响应变成:
|
|
pq: 前缀还在。%w 只是加了一层壳,底层信息照样透传。你在 HTTP 响应里加了一个"query failed"的前缀,但攻击者关心的是后面的 pq: 前缀,它直接告诉你后端是 PostgreSQL。
这不是假设场景。近年来,多个知名开源项目因错误信息泄露被发现安全漏洞。Kubernetes 就曾因日志中暴露 service account token 被报告安全问题,修复方案正是加了一层错误包装,对非管理员用户隐藏内部细节。
这说明了一个结构性问题:Kubernetes 这种级别的项目都会犯这种错,说明这不是粗心问题。没有错误分层的项目,错误泄露不是"会不会"的问题,是"什么时候"的问题。
再推演一条完整的攻击链路。你的服务对外暴露了一个 /api/users/:id 接口。数据库连接池耗尽 → db.Query 返回超时错误 → handler 里 fmt.Errorf("query failed: %w", err) 把 pq: 前缀一路透传 → HTTP 500 响应体里出现了 PostgreSQL 特征 → 攻击者确认后端是 PostgreSQL → 根据 SQLSTATE 和表名推测 schema → 下一步就有了构造针对性攻击的基础。如果你的参数化查询也有漏洞,攻击成本会大幅降低。
三层透传,每层都不觉得自己有错。db.Query 只是返回了错误,fmt.Errorf 只是包装了一下,http.Error 只是把错误写给客户端了。没人做错什么,但结果就是灾难。
问题出在哪?每一层都把底层错误原封不动地往上抛,没有做分层转换。
还有一种更隐蔽的泄露方式。很多项目用了日志中间件,会在请求结束时记录响应内容:
|
|
如果错误响应里包含了敏感信息,日志里也全有。日志系统通常是多个服务共享的,日志泄露的半径比 HTTP 响应大得多。一个开发环境的日志平台可能被几十个人访问,其中任何一个人都可能成为攻击向量。
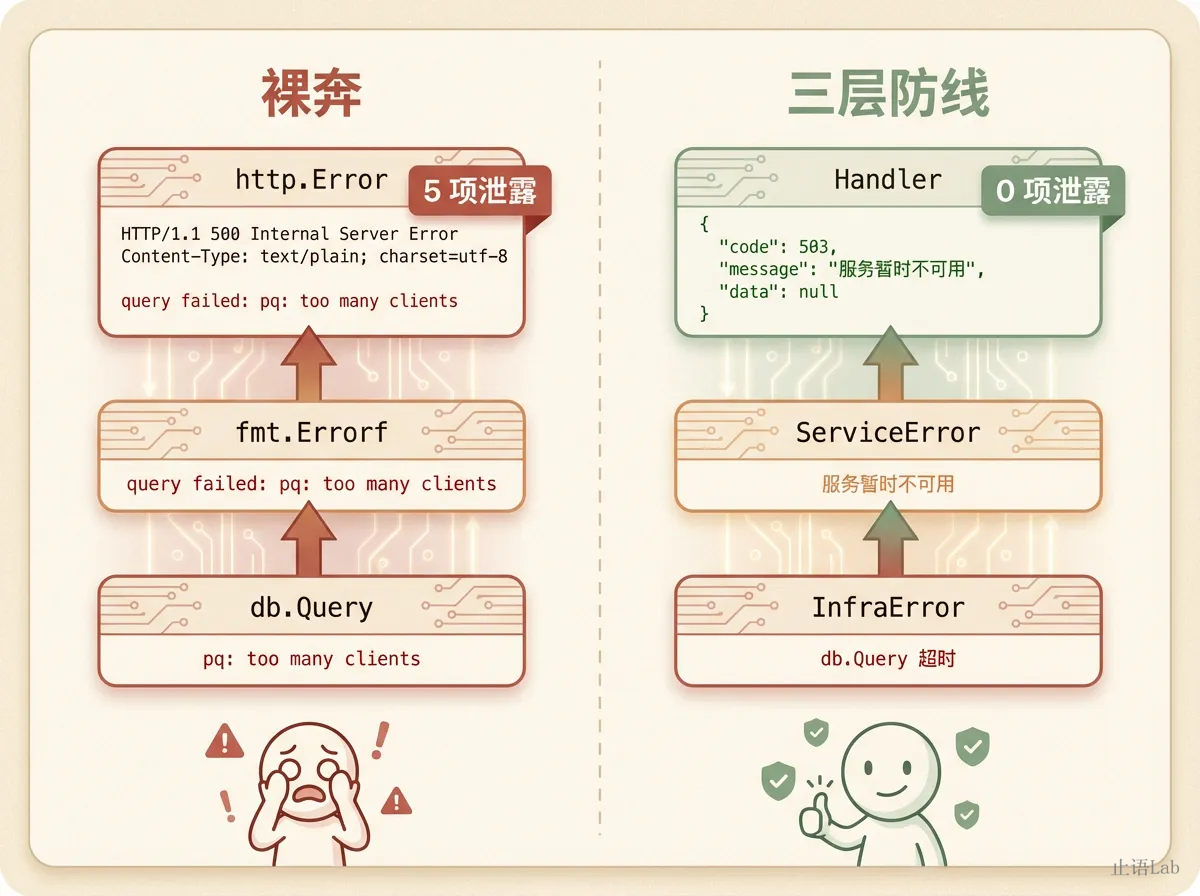
3 三层错误分层
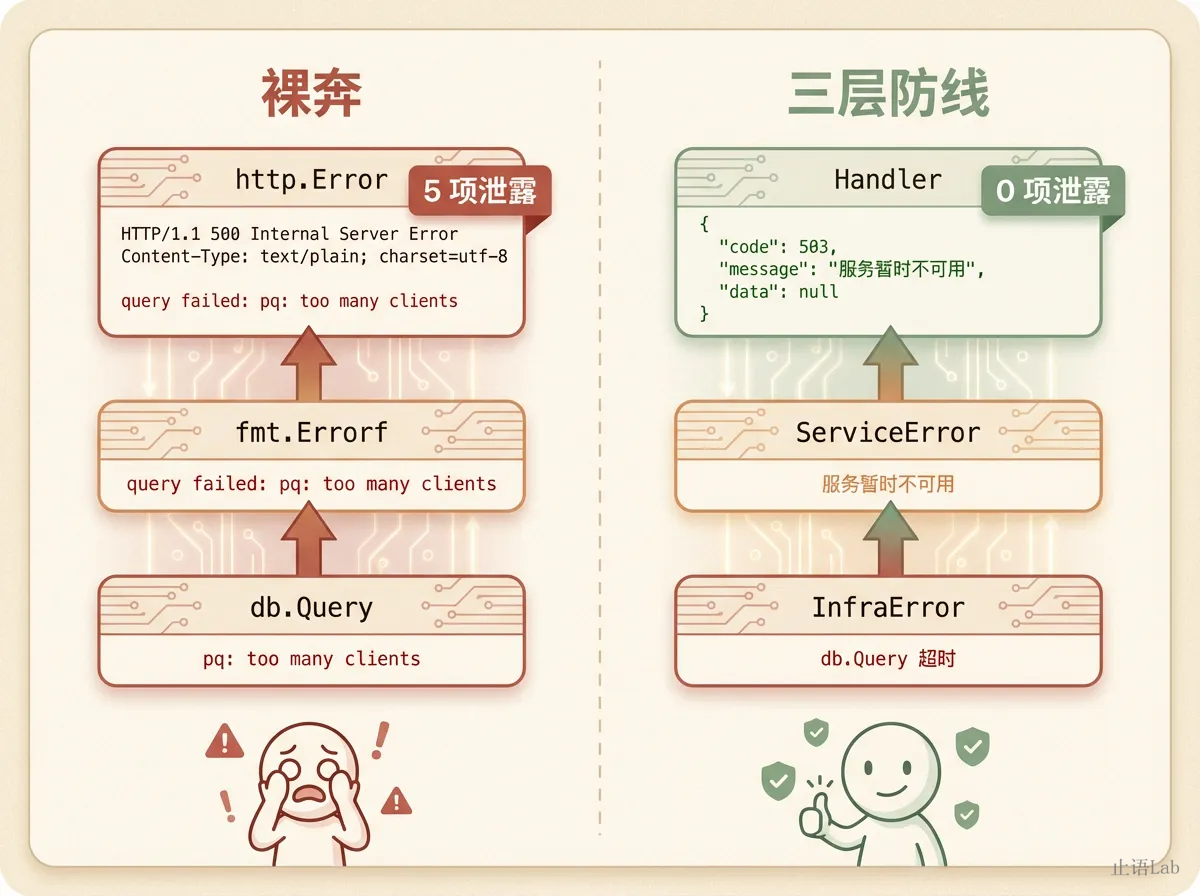
解决方案不复杂。三层就够了:
|
|
每一层有自己的错误类型,只向上暴露对上一层有意义的错误。Infra 层是物理层,Service 层是传输层,Handler 层是应用层。物理层故障不应该以原始形态暴露给应用层。当然,Go 的错误分层是约定而非强制,这要求团队的自律和 code review。
3.1 Infra 层:只报故障,不报细节
|
|
关键设计:InfraError 在 Error() 输出中包含底层信息,但这是给日志看的,不是给 HTTP 响应看的。转换的职责在 Service 层。
Infra 层的另一个职责:给错误打上操作标签。db.Query 返回的错误只有一个超时信息,但 InfraError 会告诉你"这是在执行 db.Query 操作时发生的超时",而不是"某个地方超时了"。操作标签是后续做错误路由的基础,Service 层需要知道错误发生在哪个操作上,才能决定怎么转换。
有人会问:为什么不直接在 InfraError 里加一个 IsRetryable 字段?因为可重试性是 Service 层的业务判断。同样一个数据库超时,在"创建订单"场景下可能不重试(幂等性问题),在"查询用户"场景下可以重试。Infra 层不应该替 Service 层做这个决定。
3.2 Service 层:业务语义转换
|
|
Service 层的职责是:把 Infra 层的错误转换成业务语义。数据库连接超时不是"数据库错误",是"服务暂时不可用"。用户不存在不是"查询返回空",是"用户未找到"。
这个转换不是简单的文字替换。数据库连接超时在用户看来是"服务不可用"(他不知道也不关心后端是数据库),但在运维看来是"数据库连接池需要扩容"。同一个错误,面向不同的受众,有不同的表达方式。Service 层负责面向用户的表达,运维的表达留给日志。
|
|
示例中所有 InfraError 一律转为 SERVICE_UNAVAILABLE,这是最简化的演示。实际项目中,你可能需要在 InfraError 中加一个 Kind 字段(Timeout / Permission / NotFound),Service 层据此做更精确的错误码映射。
注意:InfraError 的底层细节(数据库驱动、SQL 语句、表名)被保存在错误链里,但 Service 层不再传递它们。上层能通过 errors.As 检查错误类型做路由,但 HTTP 响应里不会出现这些细节。
这里有一个容易忽略的设计点:ServiceError.Err 保存了底层错误,这意味着 errors.As 仍然能从 Service 层的错误中提取到 Infra 层的错误类型。这在日志记录时非常有用,你可以在 handler 层统一记录完整错误链,而不需要在每一层都写日志。
但这也意味着,如果你在 handler 层直接把 ServiceError.Error() 写到 HTTP 响应里,底层信息仍然可能泄露。所以 handler 层的输出必须显式选择要暴露的字段,而不是直接调用 .Error()。
到这里,Infra 层和 Service 层的分工已经明确:Infra 只报故障类型,Service 翻译成业务语义。接下来看 Handler 层怎么用这些信息。
3.3 Handler 层:只输出安全信息
|
|
Handler 层有一个铁律:永远不把 error 的 .Error() 输出写到 HTTP 响应里。响应里只放 Message 字段和 Code 字段,这两个字段是在 Service 层精心设计的安全信息。完整的错误链只进日志。同理,绝不用 %+v 格式化错误后写入响应,那会遍历整条错误链,底层信息全部暴露。
注意最后一个 default 分支。对于未知的 Service 错误码,一律返回 500 + “internal server error”。这是防御性设计。如果你新增了一个 Service 错误码但忘了在 handler 里加 case,用户不会看到原始错误信息。
同一个数据库超时场景,经过三层处理:
|
|
零泄露。数据库驱动、SQL 语句、表名全部留在日志里,不出现在响应中。运维根据 trace_id 在日志中定位,攻击者什么都看不到。
我把两种方案做了对比实验:
| 维度 | 无分层版 | 三层分层版 |
|---|---|---|
| HTTP 状态码 | 500 | 503 |
| 响应体内容 | pq 前缀 + SQLSTATE + 库名 + SQL + 表名 | service temporarily unavailable |
| 敏感信息泄露 | 5 项 | 0 项 |
| 可观测性 | 无 trace_id | trace_id 关联日志 |
状态码从 500 变成 503 也有实际意义。500 意味着"服务器出了 bug",503 意味着"服务暂时不可用,可以稍后重试"。如果你的客户端有重试逻辑,500 不会触发重试,503 会。错误分层的收益不只是安全,还有语义正确性。
4 panic 不是你的 throw
Go 里的 panic,被太多人当成了 try-catch 的 throw。
来自 Java 或 Python 的开发者,习惯用异常做控制流。转到 Go 之后,发现 error 要一路手动传回去太麻烦,于是用 panic 来"快速返回",再在 handler 顶层 recover 一下。看起来很优雅,实际上是灾难。
翻看主流 Go 开源项目的代码,一个反复出现的模式是:大量 panic 调用可以用 error 返回替代,而项目中 panic 密度与代码库的"Go 原生度"成反比。越是 Java/Python 背景的开发者写的代码,panic 越多。
然后是性能数据。我跑了 benchmark,对比 panic+recover 和 error return 的开销:
|
|
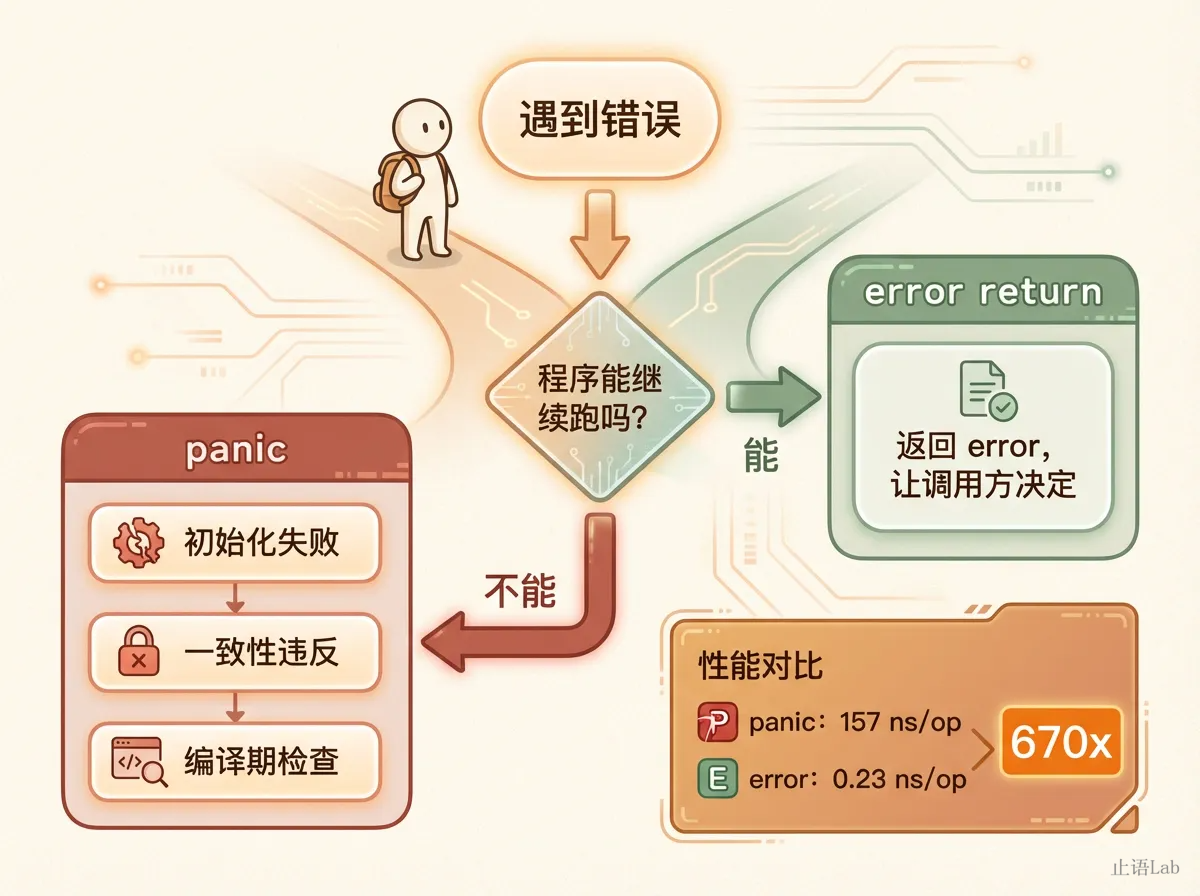
panic 比 error 慢约 670 倍,每次调用有 2 次堆分配,而 error return 是零分配。在绝大多数业务场景中,157 ns 的绝对值可以忽略。panic 的真正问题不在性能,在于丢失类型信息和错误路由能力。但在高并发热路径上,累积的 GC 压力不可忽视。
为什么会差这么多?因为 panic 的工作机制跟 error return 完全不同。panic 要遍历 goroutine 的调用栈,逐帧执行 defer,收集 recover 信息,构建堆栈跟踪字符串。而 error return 就是一个简单的值传递,编译器甚至可能把它内联掉。
4.1 panic 的正当使用场景
panic 不是不能用,而是只有极少数场景才该用。判断标准很简单:如果程序继续执行会产生比崩溃更严重的后果,panic 就是合理的。
1. 程序初始化失败
|
|
程序启动时配置缺失,跑下去也没有意义。没有数据库连接,没有缓存地址,所有请求都会失败。这时候 panic 是合理的,因为这是真正的不可恢复错误。不是"这个请求失败了",是"整个程序不应该存在"。
2. 不可恢复的一致性违反
|
|
当一个数据结构的约束被破坏,继续执行会产生错误结果,panic 是合理的。RingBuffer 的 Next 在空缓冲区上调用,说明调用方有 bug,应该立即暴露而不是返回一个零值让 bug 静默传播。
但注意,这种情况通常意味着调用方有 bug,应该在测试阶段被发现。如果你的生产环境频繁触发这种 panic,说明你的测试覆盖不够。
3. 接口实现的编译期检查
|
|
这行代码是编译期行为,不是运行时 panic。如果 MyHandler 没有实现 http.Handler 接口,编译直接报错,程序起不来。它的作用是把"运行时才发现接口没实现"的风险提前到编译期消灭。
三个场景的共同特征:错误是不可恢复的,或者应该在编译/初始化阶段就暴露。凡是运行时的业务错误,都不该用 panic。
4.2 常见的滥用模式与降级方案
滥用 1:用 panic 做"快速返回"
|
|
“快速返回"的需求本质是:调用链太长,不想一层层传 error。但这恰恰说明了你的调用链太深,需要的是重构调用链,而不是用 panic 绕过。
一个常见的辩解:“我只是把 panic 当断言用,确保前置条件成立。” 这在开发阶段说得通,但在生产环境,一个 nil order 不应该让整个服务崩溃。正确的做法是返回 error,让调用方决定怎么处理。是返回 400 告诉客户端参数有误,还是记录日志后降级处理,这个决定权不应该被 panic 剥夺。
滥用 2:用 panic+recover 做"统一错误处理”
|
|
recover 捕获的 panic 丢失了类型信息,你只能拿到一个 interface{},做不了 errors.Is/errors.As 检查,也做不了分层路由。结果是所有错误都变成 HTTP 500,回到无分层的原点。
更严重的问题:recover 之后你很难判断 panic 的来源。是数据库超时?是 nil 指针?还是除零错误?没有类型信息,你只能猜。猜测的结果就是一律返回 500,然后运维在凌晨三点被 oncall 叫醒,发现所有请求都是 500,但不知道哪里出了问题。
还有两种更隐蔽的滥用。
goroutine 内 panic 导致整个进程崩溃:
|
|
goroutine 内的 panic 如果没有 recover,会导致整个进程崩溃。Go 运行时不会替你决定怎么处理不可恢复的错误,你在 goroutine 里用 panic 的后果比在主 goroutine 里更严重。正确做法是把 error 当作普通值通过 channel 传递,让调用方决定怎么处理。
同样的逻辑也适用于用 panic 做业务"短路"。你可能写过这种代码:折扣超限时直接 panic 跳出循环。
|
|
折扣超限是业务规则违反,不是不可恢复错误。用 panic 处理业务逻辑违反了 Go 的基本设计哲学:error 是给调用方的,panic 是给运行时的。
5 Go 1.13 以来的新武器
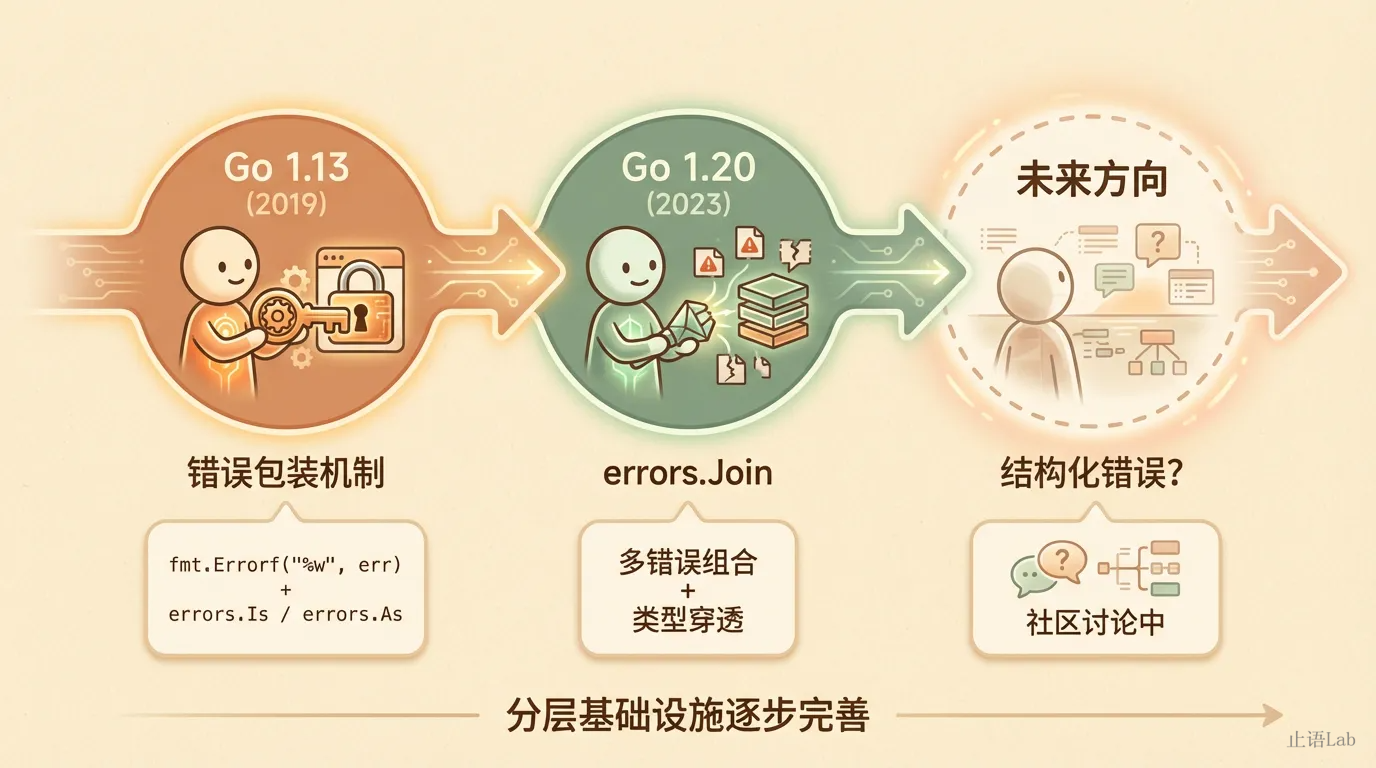
Go 1.13 引入的错误包装机制(fmt.Errorf("%w", err) + errors.Is/errors.As)是分层的基础设施。没有它,你做不了错误链检查,也就做不了分层路由。但有一个痛点:当一个操作产生多个错误时,你只能拼字符串或逐个包装。
Go 1.20 加了 errors.Join,解决了这个问题。errors.Join 返回的错误可以被 errors.Is 逐个穿透检查,而手动拼接的字符串会丢失全部类型信息:
|
|
错误组合的方式直接决定了上层的路由能力。用 errors.Join,上层可以精确判断错误类型;用字符串拼接,上层只能拿到一坨文本。
errors.Join 的实际应用场景:批量操作中的部分失败。
|
|
调用方可以检查具体是哪种错误:
|
|
一个额外收益:errors.Join 在没有任何错误时返回 nil。你可以直接 return errors.Join(errs...),不需要先判断 len(errs) > 0。在大量使用时能减少很多样板代码。
再来看一个结合三层分层的完整场景。批量导入用户时,有些用户已存在(业务错误),有些插入因为数据库超时失败(infra 错误)。Service 层需要把这两种错误区分开:
|
|
Handler 层只需要对 ServiceError.Code 做 switch,不需要关心底层是哪种 infra 错误。这是分层带来的最大好处:Handler 层的错误处理逻辑是稳定的,不会因为底层 infra 变化而变化。换数据库、加缓存、换消息队列,Handler 层的代码一行不改。
6 渐进式改造路径
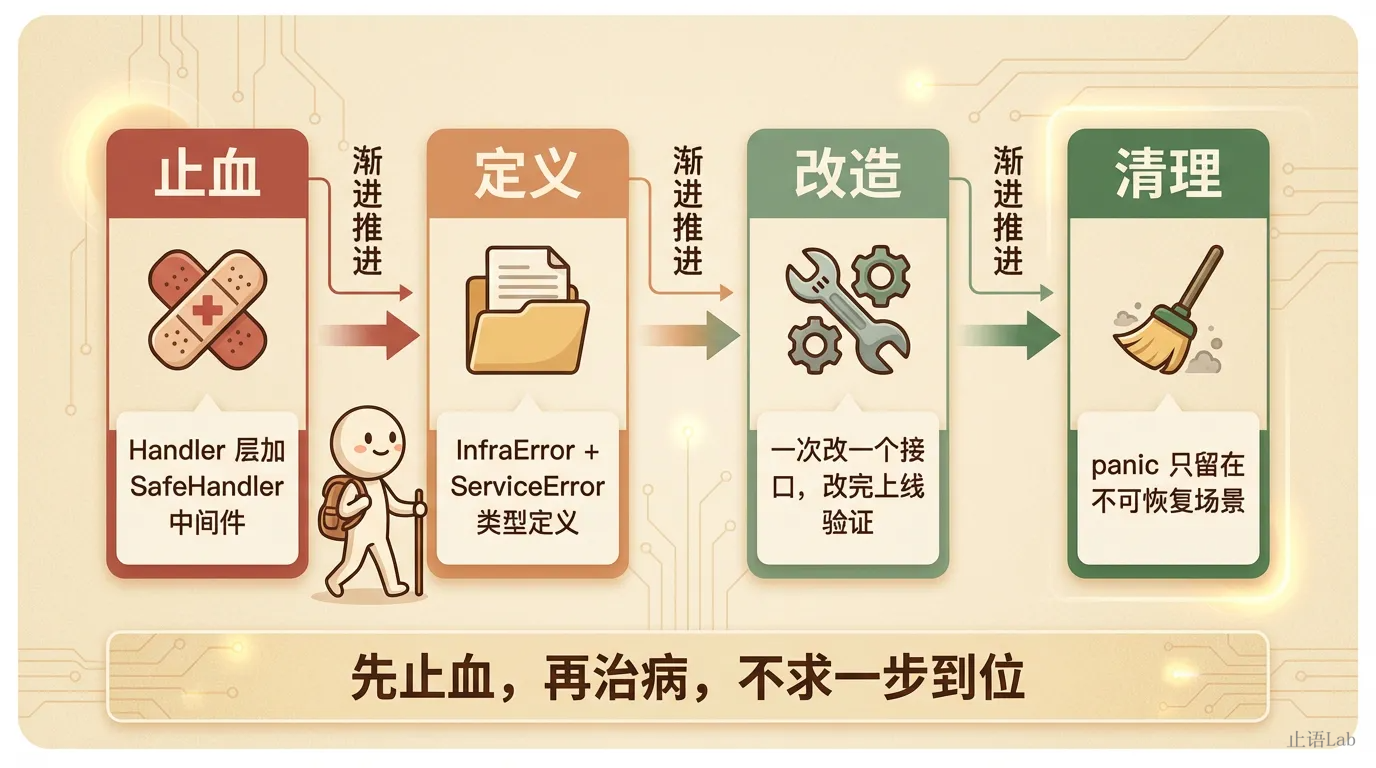
如果你有一个已经跑了一两年的项目,到处是 err.Error() 写到 HTTP 响应、panic 做快速返回、错误没有分层的代码,你不需要重写,可以渐进式改造。
关键原则:每一步改造都应该让系统比改造前更好,而不是让系统处于一个"改了一半"的不稳定状态。
6.1 第一步:止血——Handler 层加兜底
不动现有逻辑,只在 handler 最外层加一道防线:
|
|
这一步的收益:panic 不再泄露到响应体,所有未知错误都有 trace_id。成本极低,一个中间件函数搞定。
但这个中间件有个问题:它捕获所有 panic,包括那些"合理"的 panic(比如初始化失败)。更好的做法是:合理 panic 只发生在程序启动阶段,启动完成后进入 HTTP 服务阶段,此时所有 panic 都应该被捕获。
6.2 第二步:定义错误类型
在 infra/ 和 service/ 目录下各加一个 errors.go,定义 InfraError 和 ServiceError。不用改现有代码,只是把类型定义放在那里。
这一步本身不产生直接收益,但它是后续所有改造的基础。没有类型定义,后面的步骤无法进行。
一种常见的阻力:“我们的项目已经在用 pkg/errors 了,换成自定义类型改动太大。“不需要换。InfraError 和 ServiceError 可以在现有错误处理体系之上工作。你在 Infra 层用 InfraError 包装 pkg/errors 返回的错误,在 Service 层用 ServiceError 包装 InfraError。两种体系可以共存,不需要一次性迁移。
6.3 第三步:逐个接口改造
从最核心的接口开始,把 handler 里的 err.Error() 替换成类型检查和分层响应。每个接口改造的步骤:
- handler 里加
errors.As类型检查 - Service 层加错误转换(Infra → Service)
- Infra 层加
InfraError包装
一次改一个接口,改完上线验证。不需要一次性全部改完。
这里有个实操建议:改造的顺序从外到内。先改 handler 层的错误输出(确保不泄露),再改 service 层的错误转换(确保语义正确),最后改 infra 层的错误包装(确保操作标签完整)。这样每一步都是在已有防线的基础上加固,不会因为内部改造还没完成而导致新的泄露。
最常见的改造陷阱:改了 service 层新增了错误码,但忘了在对应的 handler 里加 case,导致新错误码走了 default 分支一律返回 500。建议每次新增 ServiceError.Code 时,同步搜索所有引用该 service 方法的 handler,确认 switch case 已更新。
6.4 第四步:清理 panic
在第三步推进的过程中,你会自然发现哪些 panic 可以被替换。替换标准:
| 场景 | 能否替换 | 替换方案 |
|---|---|---|
| 参数校验失败 | 能 | 返回 error |
| 外部调用失败 | 能 | 返回 error |
| 业务规则违反 | 能 | 返回 error |
| 初始化配置缺失 | 不能 | 保留 panic |
| 数据结构约束违反 | 看情况 | 测试能覆盖就改 error;不能就保留 |
“看情况"这一行需要展开说。数据结构约束违反的 panic 是否应该替换,取决于两点:一是这个约束是否在测试中能被覆盖,二是这个 panic 发生时的后果。如果测试能覆盖,说明 panic 只会在测试阶段触发,改成 error 没有实际区别。如果测试不能覆盖(比如并发竞争条件),panic 发生时你需要完整的堆栈信息来定位问题,这时候保留 panic 更有价值。
6.5 改造的优先级
不是所有代码都值得改。优先改这些:
- 面向公网的 API handler——错误泄露风险最高
- 数据库交互层——信息泄露的重灾区
- 核心业务路径——错误处理不当影响用户最大的地方
内部工具、管理后台、低流量接口,可以排到后面。先止血,再治病,不求一步到位。
有人可能会问:“这套分层方案适用于微服务吗?“适用,而且更重要。微服务之间通过 API 通信,每个服务都是一个信任边界。如果你的订单服务把数据库错误原封不动地返回给支付服务,支付服务再把错误返回给网关,跨了三个信任边界的错误透传,泄露风险比单体应用更大。三层分层的逻辑在微服务中不变,只是每一层变成了服务的内部分层,服务间的错误传递需要额外做一层"跨服务错误转换”。
在写下一行 if err != nil 之前,先过一遍这个清单:
- 你的 handler 是否直接输出了
err.Error()? - 你的错误类型是否区分了 infra 和 service?
- 你的 panic 是否只在不可恢复场景使用?
Go 官方关闭了语法变更的提案,这不是终点。恰恰相反,这是"在现有语法下做对"的起点。if err != nil 不是问题,不知道这个 error 该往哪层放才是问题。三层错误分层、panic 的正确使用场景、Go 1.13 以来的标准库新能力,这些都不需要改语言,只需要改认知。