“Don’t communicate by sharing memory, share memory by communicating.”
这句话你一定听过。很多 Go 开发者把它当成选型铁律,写并发,先用 Channel。
但 Go 标准库 sync 包里,保护共享状态用的全是 Mutex。sync.Map、sync.Pool、net/http 的连接管理——没有一个用 Channel 做状态保护。
口号是口号,工程是工程。Channel 和 Mutex 的选择从来不是哲学问题,是场景问题。
我跑了一组 benchmark,4 个典型并发场景,Channel 和 Mutex 各自实现,数据说话。
1. 对撞:同一个计数器,谁更快
测试条件:Go 1.26.2,Apple M4 Pro,GOMAXPROCS=8,testing.B 标准框架,-count=3 取均值。
三种方案保护同一个计数器:Mutex 加锁、buffered channel(1) 做令牌、atomic 原子操作:
|
|
往 ch 发送成功等于拿到令牌,接收等于归还令牌,同一时刻只有一个人能拿到。这就是用 Channel 模拟互斥锁的原理。
| 方案 | ns/op | 说明 |
|---|---|---|
| Atomic | ~30 | 基线,硬件级原子指令 |
| Channel | ~97 | buffered(1) 做互斥令牌 |
| Mutex | ~105 | 标准 sync.Mutex |
低竞争几乎打平,高竞争 Mutex 拉开差距。网上流传的"Mutex 比 Channel 快 75 倍"的说法,测试条件不一样——用的是 unbuffered channel + 额外 goroutine 做中转,相当于拿自行车和高铁比速度,赛道都不同。
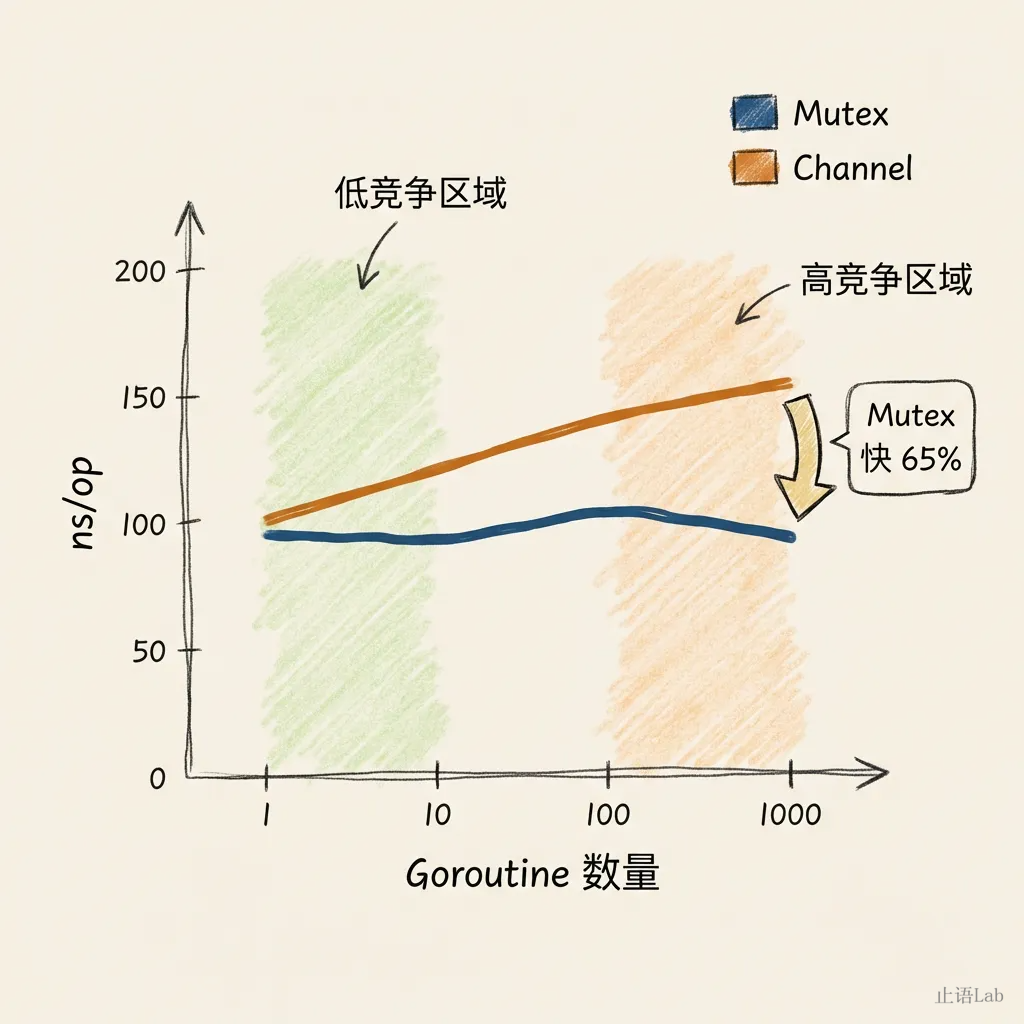
把竞争强度拉上去看趋势。固定计数器场景,变化并行 goroutine 数:
| 并行度 | Mutex ns/op | Channel ns/op | 差距 |
|---|---|---|---|
| 1 | 106 | 100 | Channel 略快 |
| 10 | 100 | 122 | Mutex 快 22% |
| 100 | 92 | 130 | Mutex 快 41% |
| 1000 | 94 | 155 | Mutex 快 65% |
Mutex 在 10-100 并行度区间 ns/op 波动在测量噪声范围内,整体趋势稳定。
竞争越激烈,Channel 越吃亏。原因是 Channel 每次收发需两次 hchan 内部锁 + buffer copy,vs Mutex 一次锁操作,高竞争下两层开销叠加。而 Mutex 在高竞争时 ns/op 增长更平缓,Go 1.9 引入的饥饿模式减少了无效自旋。
纯计数器和统计累加,atomic 是最快选择,不需要在这两者之间纠结。
2. Mutex 的主场:保护共享状态
缓存是最典型的"保护共享状态"场景:一个 map,90% 读、10% 写。
用 sync.RWMutex 和 Channel 分别实现,同等测试条件。RWMutex 把锁分成读锁和写锁,多个读操作可以同时持有读锁,互不阻塞。
|
|
| 方案 | ns/op |
|---|---|
| RWMutex | ~17.5 |
| Channel | ~456 |
RWMutex 快 26 倍。
差距的根源:RWMutex 允许多个读者并发进入,90% 的读操作几乎零等待。而 Channel 方案把所有操作(包括读)串行化到一个 manager goroutine,你有 8 个核心,但只用了 1 个。需要说明,这是社区最常见的 Channel 缓存写法,不代表 Channel 在此场景的性能上限,但更优的 Channel 实现本质上也在模仿 RWMutex 的读写分离。
这就是"保护共享状态"场景的判断依据:如果你的操作是"读多写少的状态访问",Mutex(尤其是 RWMutex)才是正解。Channel 在这里不是慢,是用错了工具。标准库的 sync.Map 对读多写少场景有专门优化,值得了解。
高竞争场景下,Mutex 会从正常模式切换到饥饿模式——当等待队列头部的 goroutine 等待超过 1ms 时,运行时将锁直接交给他,跳过自旋。这保证了公平性,但牺牲了吞吐量。(基于 runtime 源码分析,非实测)对大多数业务场景,饥饿模式触发意味着你的锁粒度太大,该拆锁了。
3. Channel 的主场:协调并发流程
工作池和管道,是 Channel 的正确舞台。
工作池的核心逻辑:N 个 worker 从同一个 Channel 取任务,Channel 天然实现了任务分发和负载均衡。
|
|
用 Mutex+Cond 实现同样的工作池,代码量翻倍,还要手动管理队列和信号通知。性能对比:
| 方案 | ns/op |
|---|---|
| Channel | ~95 |
| Mutex+Cond | ~186 |
Channel 快 2 倍,代码量少一半。 这里的关键区别:工作池不是"保护状态",是"协调流程",把任务分发给多个消费者。Channel 的 range 语义天然表达了"有任务就处理,没任务就等着,关了就退出"的完整生命周期。
管道模式同理。多阶段处理(生成→变换→聚合),Channel 连接各阶段,数据自然流动。close(ch) 向下游广播"结束"信号,不需要额外的协调逻辑:
|
|
| 方案 | ns/op | 说明 |
|---|---|---|
| Channel Pipeline | ~67 | 多阶段并发,结构清晰 |
| Sequential | ~0.22 | 顺序执行,无调度开销 |
管道的价值不在纯性能,顺序执行当然更快。管道的价值在结构:多阶段解耦、close 广播结束信号、阶段间自然背压。真实场景中每个阶段有 I/O 延迟(网络请求、文件读写),管道的并发优势才真正发挥。
Channel 通过收发配对约束防止数据竞争,是编译期保证而非运行时约定——忘了 Unlock 不会编译报错,但忘了收发 Channel 会被类型系统拦住。这是 Channel 的正确性优势。
最常见的管道翻车:用 Channel 做请求-响应模式时,如果消费者超时退出,unbuffered 的 resp channel 没人读,发送方永久阻塞——goroutine 泄漏。模拟 50 个请求,10 个超时退出后,goroutine 数从预期的 50 泄漏到 60(10 个发送方永久阻塞)。修复方式:resp channel 用 make(chan int, 1),发送方不阻塞。
4. 决策树:下次写并发代码前,先问两个问题
从上面 4 个场景提炼出来的判断框架:
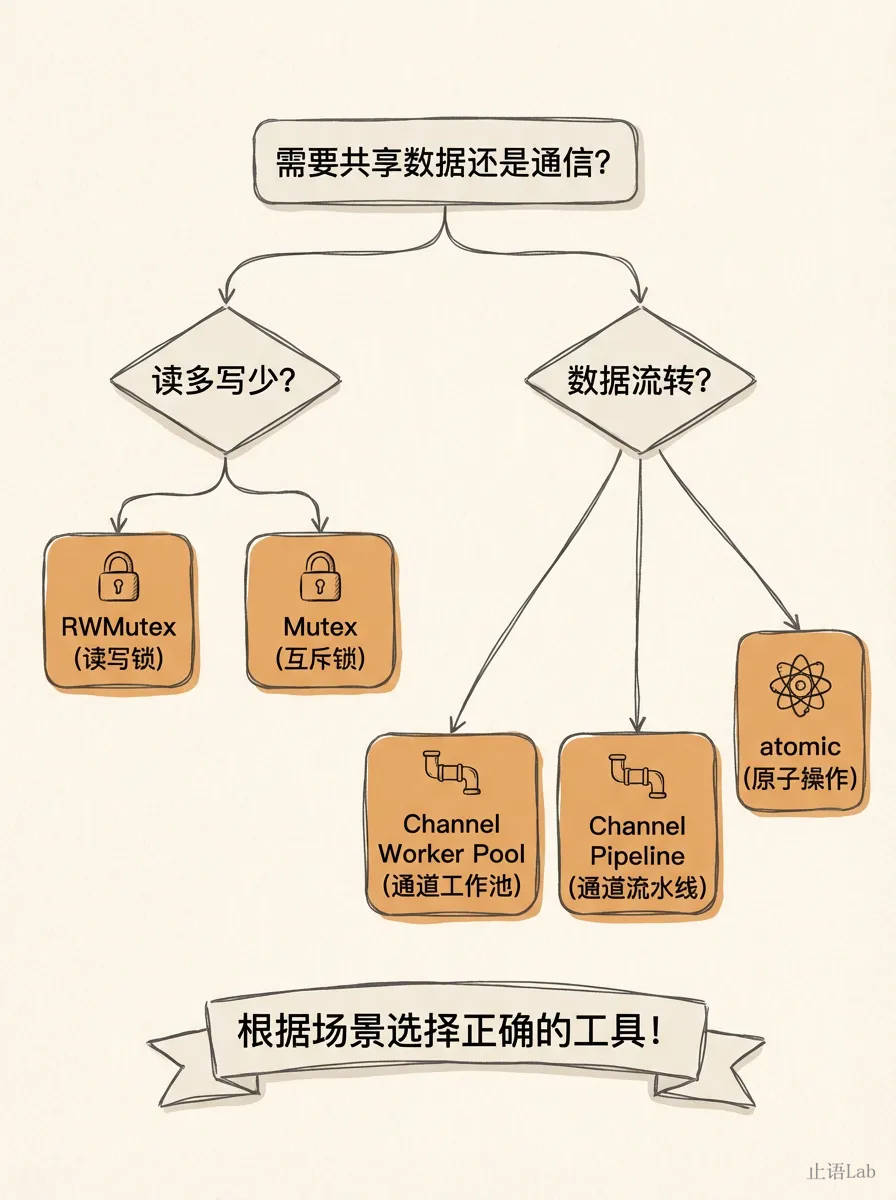
两个判断口诀:
“保护状态用锁,协调流程用管道。”
反过来说:拿 Channel 当锁用,大概率用错了;拿 Mutex 做任务队列,大概率写复杂了。
这个二分法是简化模型。真实项目中常见灰色地带:状态机(既保护状态又协调流程)、发布订阅(状态变更通知)、限流器(令牌发放+计数)。如果你的需求里"协调"权重更高(多角色协作、阶段流转),倾向 Channel 为主、Mutex 为辅;如果"保护"权重更高(读写热点数据),Mutex 为主、Channel 做通知。混合场景用 select + Channel 通知 + Mutex 保护状态,不必二选一。
下次写并发代码前,先问自己:你在保护状态,还是在协调流程?想清这一层,选型就不纠结了。