
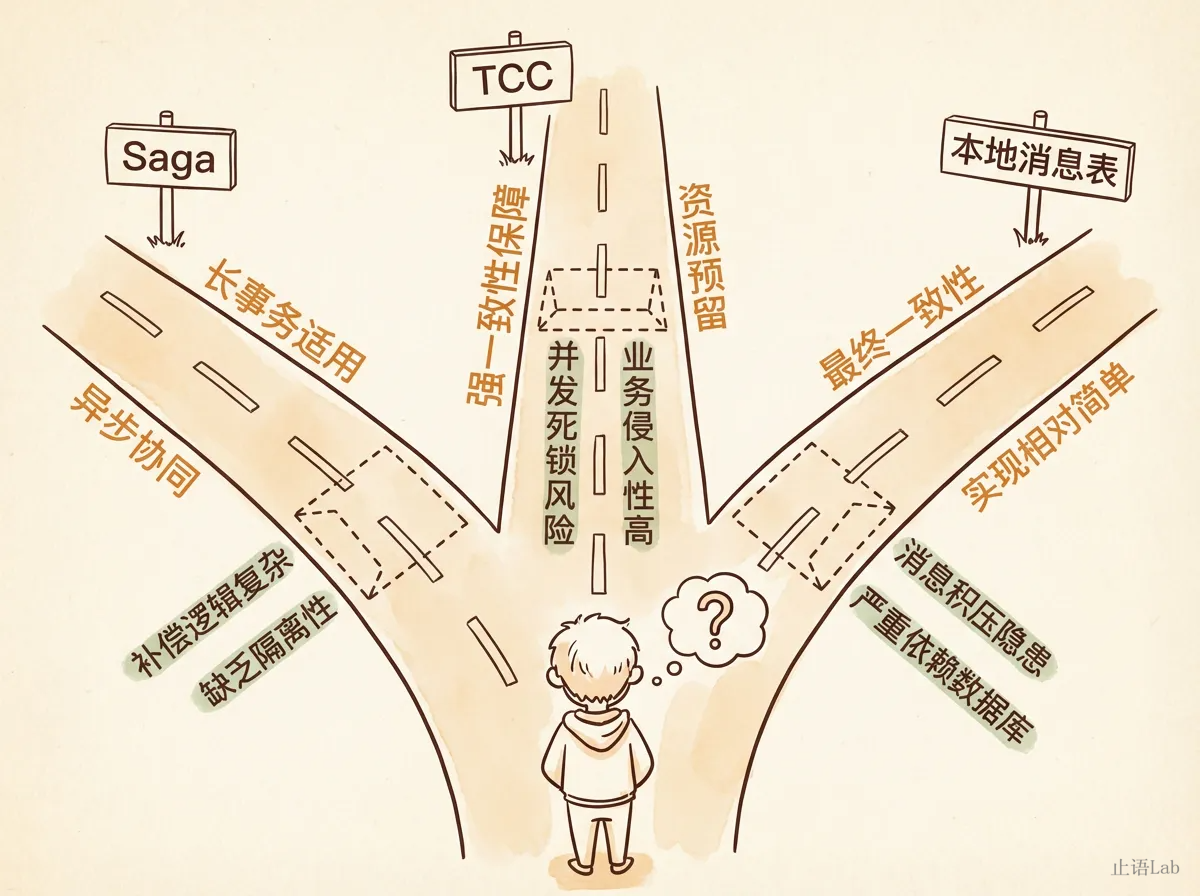
上周技术评审会上,有人问了个问题:订单服务调库存和支付,分布式事务用什么方案?
AI秒回三种方案。Saga,实现简单性能好,但补偿逻辑复杂。TCC,隔离性好一致性高,但每个服务要写三个接口。本地消息表,对业务侵入小,但有延迟。每种方案附了代码示例和架构图。
问题来了,选哪个?
AI不知道。不是分析不了,是做不了这个判断。选哪个不取决于方案本身的优缺点,取决于你的团队维护过补偿逻辑吗?你的支付服务并发高了会死锁吗?
这些信息不在任何架构文档里。只在"上次踩过坑"的人脑子里。
**“知道选项"和"做对选择"之间,隔着一整个生产事故。**这不是能力问题,是认知结构的问题。
一、知道选项,做不了选择
回到那个评审会。
AI给了三个方案,信息完整,对比清晰。但团队里的老陈听完直接否了两个:
“Saga?上次我们写补偿逻辑花了三个月,还踩了两个P0。补偿接口的幂等性和时序问题比主流程还复杂,我们团队撑不住。”
“TCC?你看过支付服务的代码吗?Try接口会锁库存,并发一高就死锁。上次用TCC,灰度第二天就回滚了。”
“本地消息表。我知道不优雅,但基础设施支持重试,团队也熟。出问题我能快速定位。”
老陈做的不是"信息分析”,是"判断"。他不是在比较方案的优缺点,而是在回答一个更本质的问题:这个团队,在这个阶段,用这套基础设施,能撑住哪个方案?
AI能列出所有选项。但"选哪个"需要的不是信息,是判断力。判断力来自上次补偿逻辑写了三个月,来自上次TCC灰度回滚,来自消息表模式跑了一年的稳稳当当。
这些经历,文档里没有。只有经历过的人才知道。
二、看不见的坑才最致命
知道选项选不了,那把经验写下来、喂给AI不就行了?
问题是,**最危险的知识是"负向知识"——不能做什么、哪里不能碰、哪些坑是已接受的坏味道。**而负向知识几乎不会被主动记录。
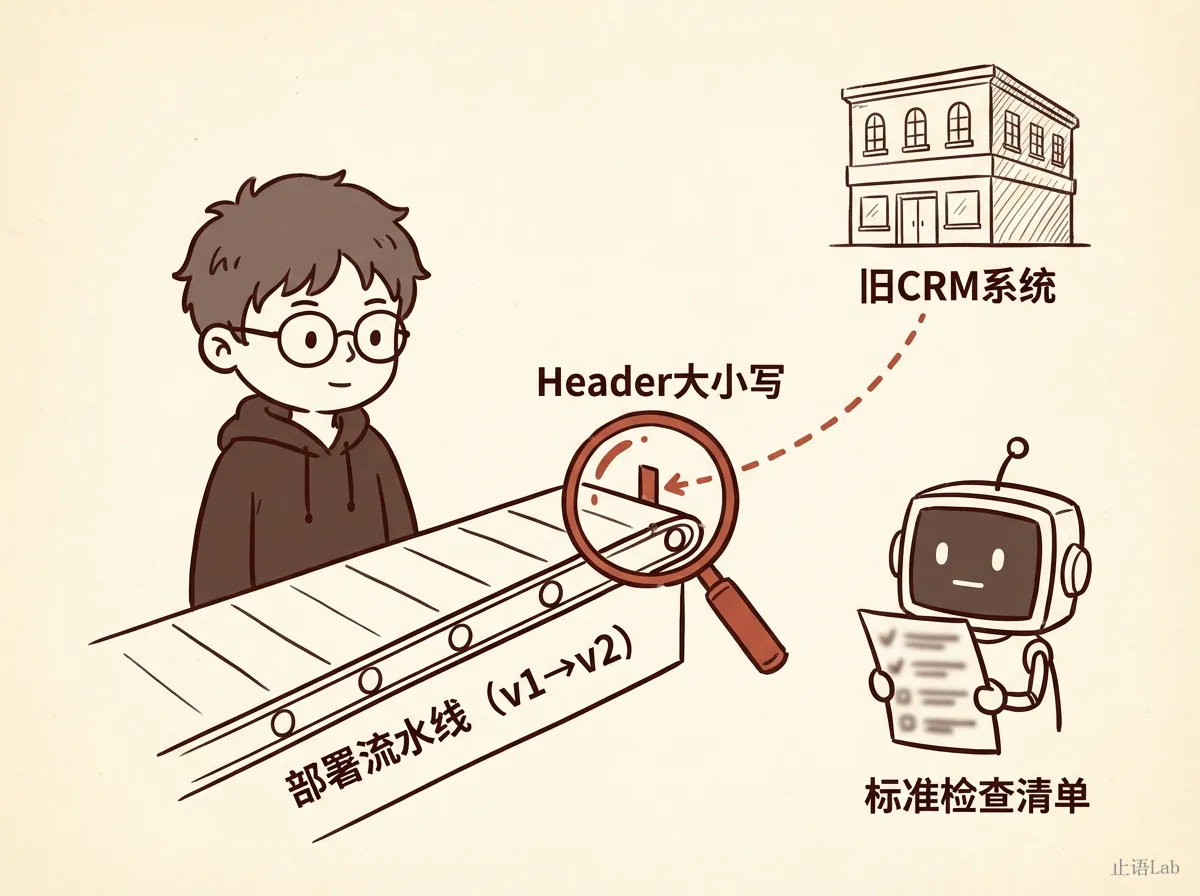
一个SaaS平台做认证服务的灰度发布,从v1升级到v2。AI给了标准流程:配置Istio流量权重,监控错误率,逐步放量。流程完全正确,配置示例也没问题。
灰度那天,5%的流量打到v2,所有通过内部CRM处理的请求全部403。
原因:下游有个5年前的老系统CRM,对接时对HTTP Header的大小写敏感。v1返回x-user-role(全小写),v2用了新的HTTP库,默认规范化成X-User-Role(首字母大写)。CRM收到大写Header,解析失败。
这个大小写敏感的问题,从未被文档记录。当初发现的人直接修了,没写Wiki。v2用了新库会改Header格式,也没人意识到——除非你记得"上次CRM因为Header报过403"。
踩过坑的人会怎么做?灰度前加一行中间件,做Header大小写转换。就这一行。但AI不会建议这行代码——它不知道CRM对大小写敏感。就算AI接入了所有内部文档和事故记录,它读到的也是"发生了什么",不是"当时为什么那么决策"——更不是"为什么以后应该这么做"。知识库解决的是信息传递,不是认知结构。
负向知识是"不能那么做",不是"应该怎么做"。AI倾向输出"最佳实践"方案,因为训练数据偏好标准答案。但生产环境需要的不是"标准答案",是"在这个满是历史技术债的系统里,哪个方案最不容易出事"。
三、有些东西就是说不出来
就算写下来了,有些东西你还是说不出来。
你debug的时候,为什么看一眼日志就知道"又是那个问题"?你说得清吗?大概率说不清。你可以说"内存泄漏",但为什么你跳过了前四步排查直接看GC日志?因为上次P0事故就是这么处理的。
你能感觉到答案,但说不出来——不是表达能力的问题,是这种判断本来就不在语言能覆盖的范围内。你自己踩过的坑,你知道那个味道,但你要跟没踩过的人描述这个味道,说不出来。
骑自行车也一样——你知道怎么保持平衡,但你说不出来。踩坑经验的结构类似:“知道"和"知道为什么"之间有不可传递的差距。
你做过三次分布式事务选型,你知道"我们团队用Saga会出事”。你可以写进文档:“不建议使用Saga,因为2024年Q3补偿逻辑写了三个月且踩了两个P0。“但三个月后,新来的同事看到这条,能判断"当前情况是否和2024年Q3一样"吗?
不能。因为他不知道当时为什么补偿逻辑写了三个月——业务复杂?团队不熟?需求变了?**文档记录了"发生了什么”,但没有记录"当时为什么这么决策”。**有人会说ADR(架构决策记录)不是记了"为什么"吗?确实。但ADR记的是决策当时的推理,不是决策之后"这个选择实际上导致了什么后果"——而后者才是判断力的真正来源。
这就是"知道规则"和"知道何时用哪个规则"的差距。规则可以文档化,“何时适用"需要判断力。判断力不能被文档传递,只能通过亲身经历获得。
你可以把所有踩坑经验写进Wiki、喂进知识库。但读Wiki的人和踩过坑的人,面对同一个决策时的反应完全不同。阅读"别人踩过的坑"和"自己踩过的坑"产生的是不同层次的判断力——前者是"知道”,后者是"知道为什么此时此地应该这么做"。不是信息差距,是认知结构差距。

四、代码会贬值,判断力不会
判断力不仅不可替代,还不可贬值。
AI让写代码的边际成本趋近于零。以前一个CRUD接口你写45分钟,现在AI写15分钟。以前搭个项目骨架要一天,现在半小时。
“我代码写得快"不再是护城河了。这层优势正在被抹平。
但有一层优势抹不平:“我知道这个方案在第三年会出问题。”
代码是会贬值的,今天写的,三年后可能被新技术替代、被重写、被遗忘。但你在某个方案上踩过的坑、做的取舍、承担的后果,不会贬值。它们长在你的判断力里,变成你面对下一个决策时的直觉。
代码商品化了,但判断力没有。判断力没法批量生产,它不是信息的汇总,而是踩坑→决策→承担后果→修正直觉的闭环。AI可以读取这个闭环的结果,但无法经历这个闭环的过程。它依赖的上下文是你的团队、你的系统、你的历史,这些上下文不能被复制,只能被经历。
你的护城河不在你写了什么代码,而在你踩过什么坑。而这个坑,AI替你踩不了。

五、出事了,AI和你的第一反应不一样
判断力在决策时管用,在故障排查时更明显。
凌晨两点,订单服务OOM告警,容器开始重启。
AI给你五步排查流程:看内存曲线,查流量变化,导出内存分析(pprof),分析占内存最多的对象,排查协程泄漏。流程完全正确,按部就班30到45分钟定位。
但经历过上次P0的工程师,第一反应不一样:
“又是OOM?先看GC频率——GC在拼命回收但内存还是涨,是泄漏不是流量。”
打开监控面板,GC频率从正常变成了每秒好几次。
“回收不动。泄漏。”
直接看内存分析里占内存最多的对象:
“上次是
orderCache没过期淘汰,这次……不是,是kafkaConsumer的offset提交卡住了,消息堆积,又没有背压保护,内存暴涨。”
从告警到根因,5分钟。
不是AI给的流程不对,是有经验的人能跳过大部分步骤,因为上次踩过。他知道先看GC频率,知道大概率是泄漏不是流量,知道先排除最可能的原因。
当然,不是每次都这么顺利——但上次踩过的坑,这次确实能跳过大部分步骤。这种"快速排除"的能力,来自亲身经历。读一百篇OOM排查指南,不如凌晨两点被叫醒处理一次。

六、经验不可省略,但可以加速
说了这么多"不可替代”,那新手怎么办?如果经验不可替代,新一代程序员怎么成长?AI把初级岗位压缩了,中高级从哪来?
答案不是"经验不可获得",而是"经验不可跳过"。
你可以读完所有游泳教材,了解自由泳的每一个动作要领。但你不亲自下水,就是不会游。教练可以让你学得更快——纠正姿势、教你换气节奏——但不能替你游。
AI就是那个教练。它可以加速你获取经验的过程:帮你跑更多实验、更快定位问题、避免已知陷阱。但有个关键区别——教练自己会游,AI不会。教练基于亲身经验教你纠正姿势,AI基于训练数据猜测你可能需要的指导。教练的"教"来自"做过",AI的"教"来自"见过"。所以AI没法替你踩坑,也没法替你为决策扛后果。
“得自己疼过才知道”,不是悲观,是认知结构的限制。你可以在疼的过程中少走弯路,但不能跳过"疼"这个环节。
如果经验的结构性不可替代,那经验传递的正确方式不是"写文档",而是"创造经历"——所以如果你是团队里的老手,别只写文档,带新人做一次生产事故复盘,比写十页Wiki有用。如果你是新人,别只读文档,主动参与灰度发布、故障排查,让"别人的经验"变成"你的经历"。
经验不可省略。但可以加速。

AI能读完所有文档。但文档里不会写"上次我们踩过这个坑"。
你的判断力不靠背架构模式,也不靠读技术博客。它在你踩过的坑里、做过的取舍里、为某个决策扛过的后果里。
这些东西,AI读不到。你的同事也读不到。只有你自己经历过才知道。
这不是AI目前不行的局限,是认知结构的限制。不管AI多强,有些知识只能通过亲身经历获得。就像你可以读完所有游泳教材,但不下水就是不会,“知道"和"会"之间,隔着一整个水。