这篇文章讲什么
你手上有个任务:调研 5 个竞品的功能、价格和用户评价,写成一份对比报告。手动搜索、逐个整理,大概要花半天。但如果你有一组 AI Agent,各自负责搜索、分析、汇总——接入真实搜索 API 后,整个过程可以压缩到几分钟。
这就是多 Agent 系统的价值:让 AI 分工协作,自动完成复杂的多步任务。
本文会带你从零开始,用 Claude API 搭建一个多 Agent 系统的完整框架。不需要框架,不需要复杂的基础设施,只要 Python 和一个 API Key。
你会学到:
- Agent 是什么,跟普通的 LLM 调用有什么区别
- 如何写一个能自主调用工具的单 Agent
- 如何把多个 Agent 组织成团队,让它们分工协作
- 动手搭一个竞品调研系统的骨架(含模拟搜索,换成真实 API 即可投产)
- 避坑指南:Token 消耗、上下文污染、调试技巧
适合谁读: 有 Python 基础、用过 ChatGPT 或 Claude、但没接触过 Agent 开发的开发者。
1. Agent 是什么,为什么要"多"
先把概念理清。
Agent(智能体) —— 能自主规划、调用工具、执行任务的 AI。跟普通的 LLM 调用不一样,Agent 不只是"你问我答",它能自己决定下一步做什么。
打个比方:普通的 LLM 调用像客服热线,你问一句它答一句;Agent 更像你雇的助理——你说"帮我调研竞品",它会自己拆解任务、上网搜索、整理结果。
两者的区别可以用一张表说清楚:
|
普通 LLM 调用 |
Agent |
| 交互方式 |
一问一答,每次独立 |
多轮自主决策 |
| 外部工具 |
需要人写代码串联 |
自己决定调用哪个工具 |
| 任务复杂度 |
单步任务 |
多步任务 |
| 决策权 |
人决定每一步 |
AI 自己决定下一步 |
那为什么要"多" Agent?
原因有两个。
一是专业化分工。 把所有工具塞给一个 Agent,就像让一个人同时当搜索工程师、数据分析师和报告撰写人。它哪个都能凑合,但哪个都不精。拆成多个专门的 Agent,每个只关注自己的领域,Prompt 更短、工具更少、输出更稳定。
二是并行效率。 多个 Agent 可以同时干活。比如竞品调研,搜索 5 个竞品的信息——一个 Agent 串行搜要五次,五个 Agent 并行搜只要一次的时间。
Anthropic 在他们的多 Agent 研究系统中做过对比:由 Claude Opus 4 当编排器、多个 Claude Sonnet 4 当子 Agent 的系统,在内部研究评估(internal research eval)上的得分比单独使用 Opus 4 高出约 90%(来源:Anthropic 官方博客)。他们分析发现,Token 用量本身就能解释 80% 的性能差异——本质上是用更多的计算资源换取更好的结果。
不过代价也很明显。Anthropic 的生产数据显示:单 Agent 的 Token 消耗约是普通聊天的 4 倍,多 Agent 系统约是 15 倍。所以它更适合高价值的复杂任务,不是什么都往上面套。
什么时候该用多 Agent? 一个简单的判断标准:
- 任务能拆成 2 个以上独立的子任务 → 考虑多 Agent
- 子任务之间不需要频繁交换中间状态 → 适合多 Agent
- 任务简单、步骤少、一个 Prompt 就能搞定 → 单 Agent 足够
- 所有子任务必须共享同一份上下文 → 不适合多 Agent
还有一个概念提一下:MCP(Model Context Protocol) —— AI 与外部工具连接的开放标准。你可以理解为:REST 是 Web API 的通用语言,MCP 就是 AI 工具集成的通用语言。目前 OpenAI、Google DeepMind、百度等都已采用。本文的代码用的是 Claude 的原生 Tool Use,不依赖 MCP,但了解 MCP 有助于理解工具生态的方向。
你只需要知道:Agent = 能自己调工具的 AI。当任务需要多种专业能力协作,或者能拆成独立子任务并行处理时,多 Agent 就有价值。代价是 Token 消耗会大幅增加。
2. 从单 Agent 开始
别一上来就搞多 Agent。先搞定单 Agent,理解它的运行机制。
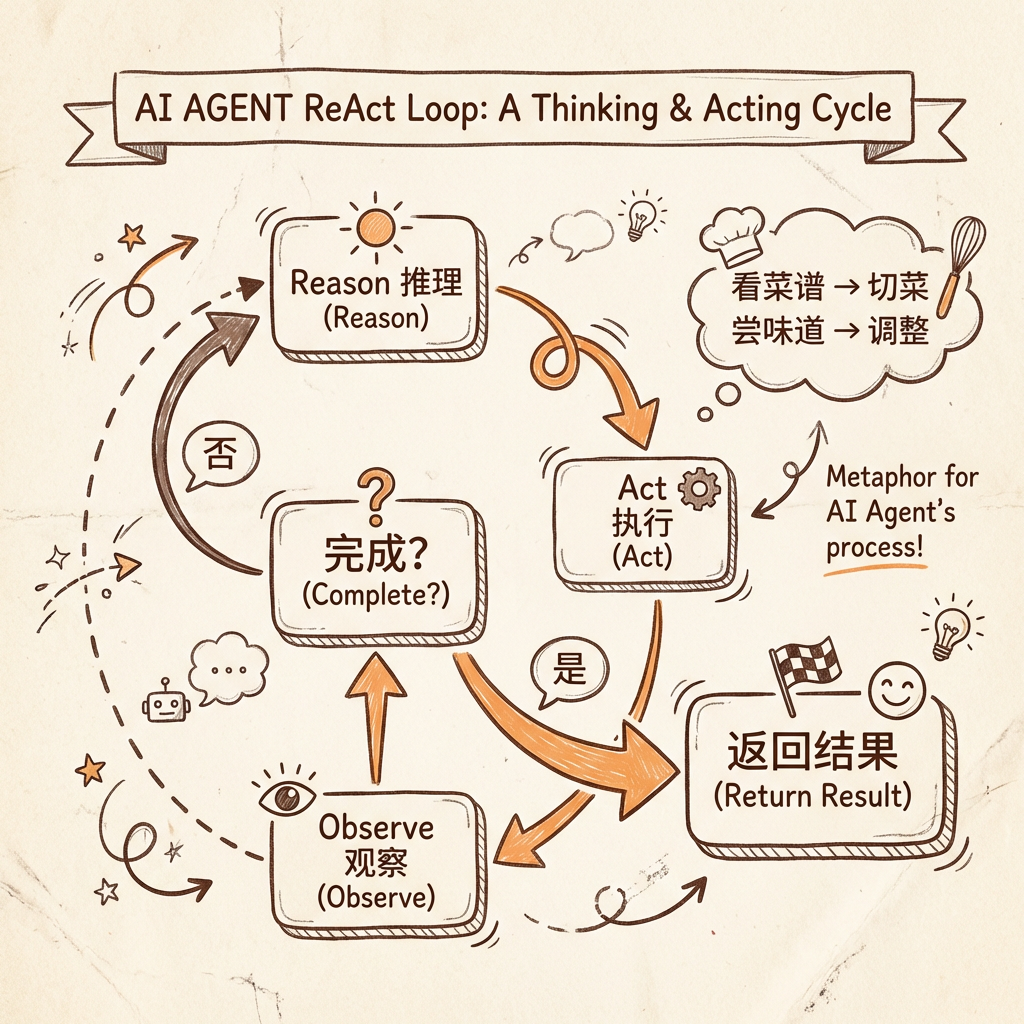
ReAct:Agent 的工作循环
ReAct 模式(Reasoning + Acting) —— Agent 的核心工作方式,一个"推理→执行→观察"的循环。
用做饭来类比:看菜谱(推理)→ 切菜(执行)→ 尝味道(观察)→ 觉得淡了再加盐(推理)→ 加盐(执行)→ 再尝(观察)。Agent 的工作方式一模一样。
写你的第一个 Agent
下面用 Claude API 写一个能搜索网页的 Agent。代码基于 anthropic Python SDK(模型:claude-sonnet-4-20250514)。
先装依赖、设 API Key:
1
2
|
pip install anthropic
export ANTHROPIC_API_KEY="你的API密钥"
|
完整代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
|
import anthropic
import json
client = anthropic.Anthropic()
tools = [
{
"name": "web_search",
"description": "搜索互联网获取实时信息。输入搜索关键词,返回搜索结果摘要。",
"input_schema": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
}
},
"required": ["query"]
}
}
]
def execute_tool(name: str, params: dict) -> str:
"""工具执行入口——目前是模拟数据,替换为 Tavily/SerpAPI 即可接入真实搜索"""
if name == "web_search":
return f"搜索'{params['query']}'的结果:这里是模拟的搜索结果..."
return "未知工具"
def run_agent(task: str) -> str:
"""运行单 Agent 的 ReAct 循环"""
messages = [{"role": "user", "content": task}]
while True:
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=4096,
tools=tools,
messages=messages,
)
# Agent 决定任务完成,返回结果
if response.stop_reason == "end_turn":
for block in response.content:
if hasattr(block, "text"):
return block.text
# 安全兜底:max_tokens 截止时也返回已有内容
if response.stop_reason == "max_tokens":
for block in response.content:
if hasattr(block, "text"):
return block.text
return "Agent 输出被截断,请增大 max_tokens"
# Agent 要求调用工具
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = execute_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
# 把 Agent 的回复和工具结果都加到对话历史
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
result = run_agent("搜索一下 2026 年最流行的 Python Web 框架有哪些")
print(result)
|
这段代码的核心是三件事。
定义工具。 告诉 Claude"你有一个搜索工具可以用"。工具定义用 JSON Schema 格式,包括名称、描述和参数。
ReAct 循环。 每次回复后检查 stop_reason:如果是 end_turn,说明 Agent 觉得任务完了;如果它调用了工具(tool_use),就执行工具、把结果喂回去,继续循环。注意代码里也处理了 max_tokens 截止的情况——不处理这个,Agent 输出太长时会陷入死循环。
对话历史。 每轮循环把 Agent 的回复和工具结果追加到 messages。这样 Agent 能记住之前做了什么。
Prompt(提示词) —— 给 Agent 的指令和约束。上面代码里的 task 参数就是最简单的 Prompt。好的 Prompt 应该说清楚三件事:你是谁、你要做什么、用什么格式输出。
Agent 自动规划搜索顺序——你不需要告诉它"先搜 FastAPI 再搜 Django"。
你只需要知道:Agent 的核心是 ReAct 循环——推理、执行、观察、再推理。用 Claude API 实现只需要一个 while 循环 + 工具定义。
3. 升级到多 Agent
上一节搞定了单 Agent。但当任务涉及多个领域——比如既要搜索信息、又要分析数据、还要生成报告——一个 Agent 的 Prompt 就得又长又复杂。每加一个工具,它对每个工具的理解都会被"稀释"一点。
这时候多 Agent 就有意义了。
编排器-子 Agent 架构
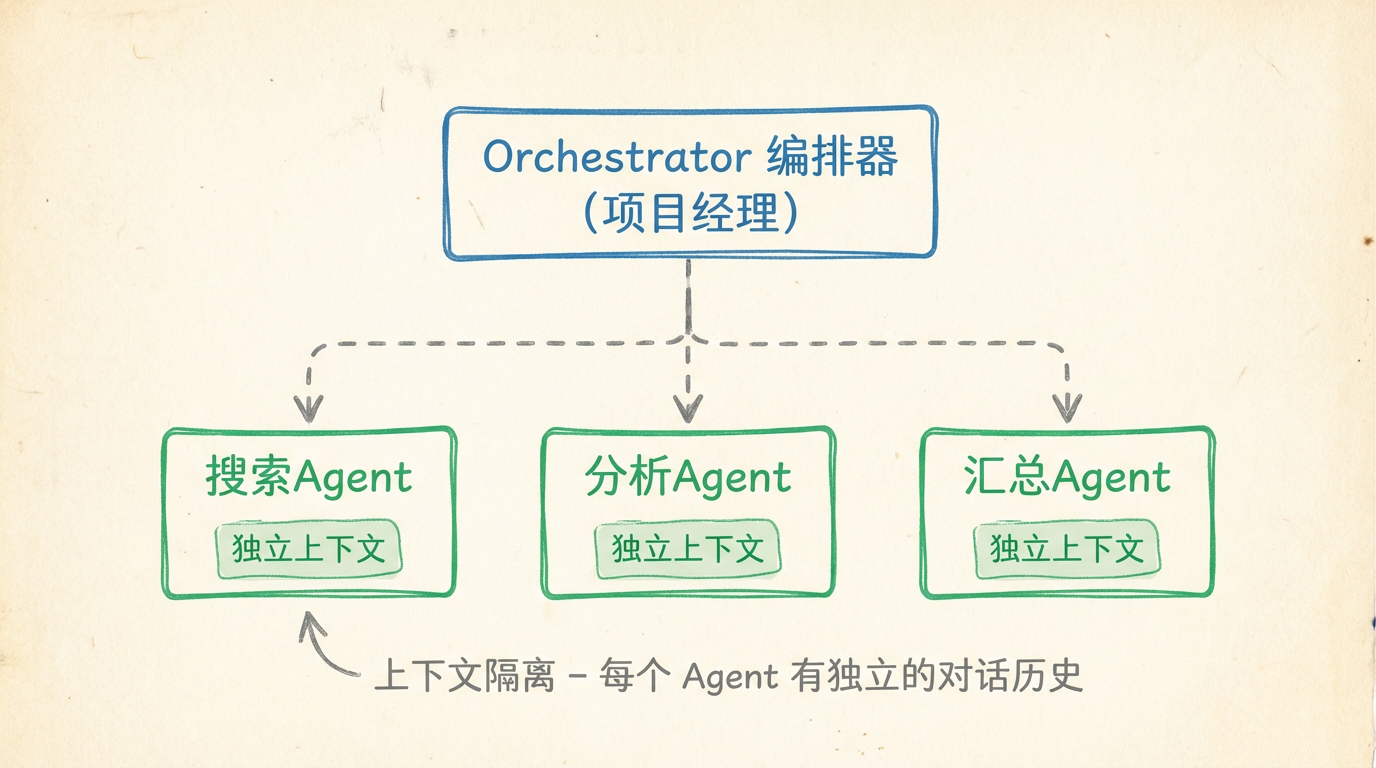
多 Agent 系统的核心架构叫 Orchestrator-Subagent(编排器-子 Agent)。
编排器(Orchestrator) —— 负责任务分配和协调的主 Agent。像项目经理,不亲自干活,负责拆解任务、分配给合适的人、汇总结果。
子 Agent(Subagent) —— 执行具体任务的专门 Agent。每个只管自己的领域。
上下文隔离:为什么要分开
这里有个关键设计:上下文隔离(Context Isolation) —— 每个 Agent 有独立的对话历史,互不干扰。
上下文隔离就像分会议室开会——每个人先在自己的小会议室研究自己的部分,最后只向项目经理汇报结论。不需要知道其他人搜了什么、看了哪些资料。
在技术层面,上下文隔离带来两个好处:
- 每个 Agent 的上下文窗口只包含自己需要的信息,不会被其他任务的内容"稀释"
- 子 Agent 只返回压缩后的结论给编排器,不是把搜索中的所有中间结果都传回去
代码实现
基于上一节的 execute_tool 函数,搭一个多 Agent 系统:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
|
import anthropic
import json
import re
from concurrent.futures import ThreadPoolExecutor
client = anthropic.Anthropic()
def create_subagent(system_prompt: str, task: str, tools: list = None) -> str:
"""创建并运行一个独立的子 Agent"""
# 关键:每个子 Agent 都有全新的 messages,这就是上下文隔离
messages = [{"role": "user", "content": task}]
while True:
kwargs = {
"model": "claude-sonnet-4-20250514",
"max_tokens": 4096,
"system": system_prompt,
"messages": messages,
}
if tools:
kwargs["tools"] = tools
response = client.messages.create(**kwargs)
if response.stop_reason in ("end_turn", "max_tokens"):
for block in response.content:
if hasattr(block, "text"):
return block.text
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = execute_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
def extract_json(text: str) -> dict:
"""从 LLM 输出中提取 JSON——处理 markdown 代码块包裹的情况"""
# 先尝试直接解析
try:
return json.loads(text)
except json.JSONDecodeError:
pass
# 尝试提取 ```json ... ``` 中的内容
match = re.search(r'```(?:json)?\s*([\s\S]*?)```', text)
if match:
try:
return json.loads(match.group(1).strip())
except json.JSONDecodeError:
pass
# 尝试提取第一个 { ... } 块
match = re.search(r'\{[\s\S]*\}', text)
if match:
try:
return json.loads(match.group(0))
except json.JSONDecodeError:
pass
raise ValueError(f"无法从 LLM 输出中提取 JSON: {text[:200]}")
def run_orchestrator(task: str) -> str:
"""编排器:拆解任务 → 并行分配 → 汇总结果"""
# 第一步:让编排器分析任务,拆成子任务
plan_response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=2048,
system="""你是一个任务编排器。分析用户任务,拆解成可并行的子任务。
用 JSON 格式输出,格式如下:
{"subtasks": [{"name": "任务名", "prompt": "子Agent的角色描述", "task": "具体任务"}]}""",
messages=[{"role": "user", "content": task}],
)
plan = extract_json(plan_response.content[0].text)
# 第二步:并行启动子 Agent
results = {}
with ThreadPoolExecutor(max_workers=5) as executor:
futures = {}
for subtask in plan["subtasks"]:
future = executor.submit(
create_subagent,
system_prompt=subtask["prompt"],
task=subtask["task"],
)
futures[subtask["name"]] = future
for name, future in futures.items():
results[name] = future.result()
# 第三步:汇总
summary = create_subagent(
system_prompt="你是信息汇总专家。把多个研究结果整合成结构清晰的报告。",
task=f"以下是各子任务的结果,请综合整理:\n{json.dumps(results, ensure_ascii=False, indent=2)}",
)
return summary
|
代码结构分两部分:
create_subagent —— 创建独立的子 Agent。每次调用都是全新的 messages,这就是上下文隔离。注意 stop_reason 同时处理了 end_turn 和 max_tokens。run_orchestrator —— 编排器分三步走:分析任务 → 并行执行 → 汇总结果。
这里多了一个 extract_json 函数。这是 Agent 开发中的常见问题:你让 LLM 返回纯 JSON,它有时会在前后加上解释文字,或者用 markdown 代码块包裹。直接 json.loads() 会报错。这个函数逐级尝试三种提取策略,实际项目中很实用。
还有一个设计选择:编排器用的也是 Sonnet 4。在 Anthropic 的研究中,他们用 Opus 4 当编排器、Sonnet 4 当子 Agent,效果更好。但对于入门项目,统一用 Sonnet 就够了——先跑通,再优化。
你只需要知道:多 Agent 系统的核心是"编排器 + 子 Agent"。编排器负责拆解和分配,子 Agent 各自在独立的上下文中执行。用 ThreadPoolExecutor 可以让子 Agent 并行运行。
4. 动手搭一个竞品调研系统
理论讲完了,来搭一个完整的东西。
目标:输入一个产品名称,输出一份竞品分析报告——包括功能对比、定价信息和用户评价。代码用模拟搜索演示架构,替换 execute_tool 中的搜索逻辑为真实 API(如 Tavily、SerpAPI)即可投入使用。
系统架构
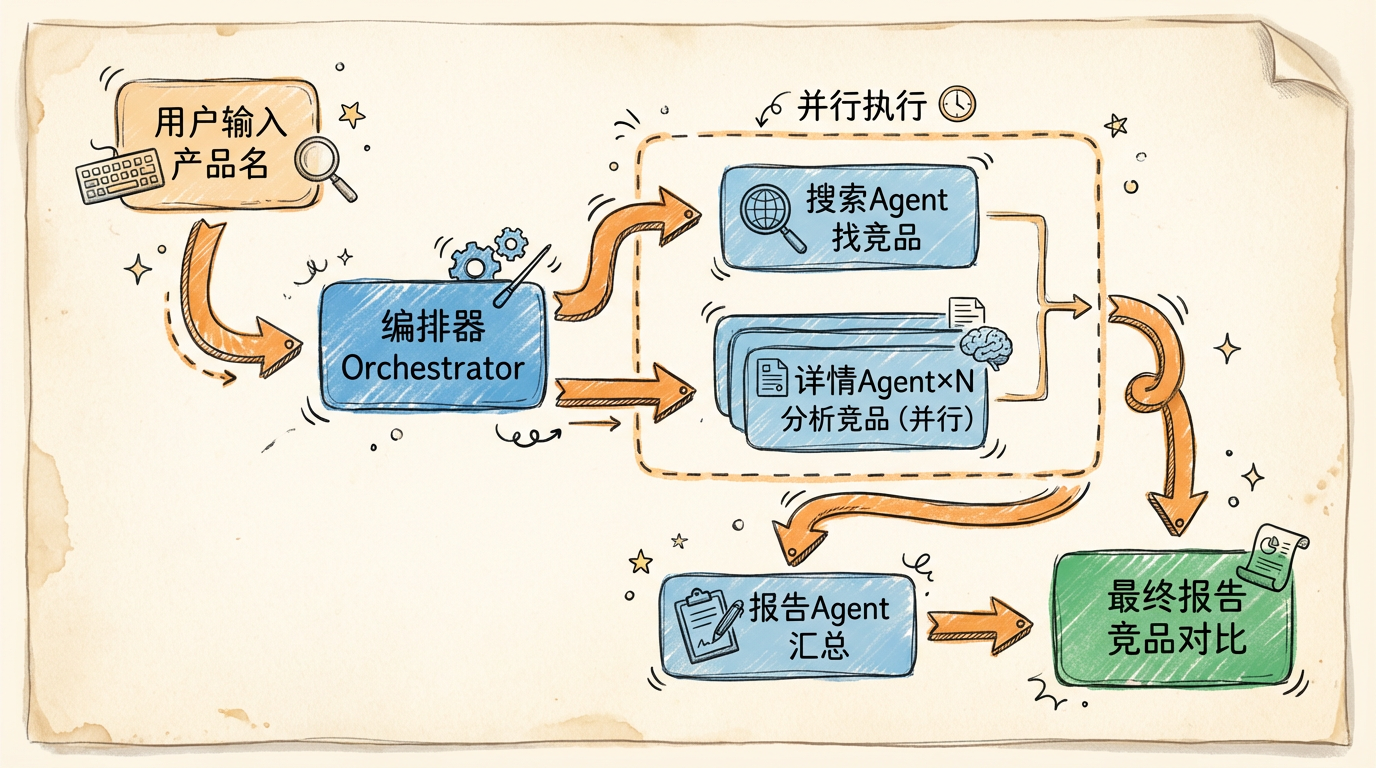
三个 Agent 各司其职:搜索 Agent 找竞品列表,详情 Agent 并行分析每个竞品,报告 Agent 汇总对比。
完整代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
|
import anthropic
import json
import re
from concurrent.futures import ThreadPoolExecutor
client = anthropic.Anthropic()
search_tool = {
"name": "web_search",
"description": "搜索互联网获取产品信息、评价和定价数据。输入搜索关键词,返回相关结果摘要。",
"input_schema": {
"type": "object",
"properties": {
"query": {"type": "string", "description": "搜索关键词"}
},
"required": ["query"]
}
}
def execute_tool(name: str, params: dict) -> str:
"""工具执行入口——目前是模拟数据,替换为真实搜索 API 即可投产"""
if name == "web_search":
return f"搜索结果:{params['query']} 的相关信息..."
return "未知工具"
def create_subagent(role: str, task: str, tools: list = None) -> str:
"""创建子 Agent,运行到完成"""
messages = [{"role": "user", "content": task}]
while True:
kwargs = {
"model": "claude-sonnet-4-20250514",
"max_tokens": 4096,
"system": role,
"messages": messages,
}
if tools:
kwargs["tools"] = tools
response = client.messages.create(**kwargs)
if response.stop_reason in ("end_turn", "max_tokens"):
for block in response.content:
if hasattr(block, "text"):
return block.text
tool_results = []
for block in response.content:
if block.type == "tool_use":
result = execute_tool(block.name, block.input)
tool_results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": result,
})
messages.append({"role": "assistant", "content": response.content})
messages.append({"role": "user", "content": tool_results})
def extract_json(text: str) -> dict:
"""从 LLM 输出中提取 JSON(处理 markdown 代码块等干扰)"""
try:
return json.loads(text)
except json.JSONDecodeError:
pass
match = re.search(r'```(?:json)?\s*([\s\S]*?)```', text)
if match:
try:
return json.loads(match.group(1).strip())
except json.JSONDecodeError:
pass
match = re.search(r'\{[\s\S]*\}', text)
if match:
try:
return json.loads(match.group(0))
except json.JSONDecodeError:
pass
raise ValueError(f"无法提取 JSON: {text[:200]}")
def research_competitors(product_name: str) -> str:
"""竞品调研完整流程"""
# 第一步:搜索 Agent 找出主要竞品
competitors_raw = create_subagent(
role="""你是竞品搜索专家。找出给定产品的 3-5 个主要竞品。
返回纯 JSON,格式:{"competitors": ["竞品1", "竞品2", ...]}""",
task=f"找出 {product_name} 的主要竞品",
tools=[search_tool],
)
# 解析竞品列表——LLM 返回不一定是纯 JSON,需要鲁棒解析
try:
competitors = extract_json(competitors_raw)["competitors"]
except (ValueError, KeyError):
competitors = ["竞品A", "竞品B", "竞品C"]
# 第二步:并行收集每个竞品的详细信息
details = {}
with ThreadPoolExecutor(max_workers=len(competitors)) as executor:
futures = {}
for comp in competitors:
future = executor.submit(
create_subagent,
role="你是产品分析专家。搜索并整理产品的功能亮点、定价方案和用户评价。输出结构化的分析结果。",
task=f"详细分析产品:{comp}",
tools=[search_tool],
)
futures[comp] = future
for comp, future in futures.items():
details[comp] = future.result()
# 第三步:汇总 Agent 生成对比报告
report = create_subagent(
role="你是商业分析报告专家。把多个产品的分析结果整合成一份结构清晰的竞品对比报告。",
task=f"""原始产品:{product_name}
各竞品分析结果:
{json.dumps(details, ensure_ascii=False, indent=2)}
请生成竞品对比报告,包含:
1. 竞品概览(一句话定位)
2. 功能对比矩阵
3. 定价对比
4. 各产品优劣势
5. 选型建议""",
)
return report
if __name__ == "__main__":
report = research_competitors("Notion")
print(report)
|
核心设计思路:
- 搜索 Agent 只找竞品名单,不做分析——职责单一
- 详情 Agent 每个竞品独立分析,互不影响——上下文隔离
- 报告 Agent 只做汇总,拿到的是压缩后的结论——减少 Token
- 详情 Agent 用
ThreadPoolExecutor 并行跑——效率高
注意 extract_json 的使用:LLM 有时会在 JSON 前后加文字说明,或者用 markdown 代码块包裹。这在 Agent 系统中很常见,做好防御性解析能省很多调试时间。
这个例子用了模拟搜索——实际项目中,把 execute_tool 里的搜索逻辑替换成 Tavily、SerpAPI 或者 Claude 的内置 Web Search 工具就行。核心架构不变。
你只需要知道:把任务拆成"搜索→分析→汇总"三步,每步交给专门的 Agent。详情分析并行跑,汇总串行跑。搜索工具换成真实 API 即可投产。
5. 避坑指南
搭多 Agent 系统的框架不复杂,但从 demo 到稳定运行,有几个坑需要提前知道。
坑 1:Token 消耗失控
Token(令牌) —— AI 处理文本的基本单位,也是计费单位。一个中文字大约 1-2 个 Token。
多 Agent 系统的 Token 消耗远高于单 Agent。Anthropic 的生产环境数据(来源):
| 系统类型 |
Token 消耗(相对值) |
适用场景 |
| 普通聊天 |
1x(基准) |
简单问答 |
| 单 Agent |
~4x |
多步任务 |
| 多 Agent |
~15x |
复杂并行任务 |
具体消耗取决于任务复杂度、子 Agent 数量和工具调用轮次。上面的倍数是 Anthropic 在研究系统中的平均值。
怎么控制:
- 子 Agent 只返回精简摘要,不要把完整搜索结果传给编排器
- 用
max_tokens 限制每个 Agent 的输出长度
- 简单任务别用多 Agent——杀鸡别用牛刀
坑 2:上下文污染
如果你不小心让多个 Agent 共享了同一个 messages 列表,它们的对话历史会互相污染。A Agent 搜索的结果跑到 B Agent 的上下文里,B Agent 就可能产出莫名其妙的回答。
解法: 每个子 Agent 都用全新的 messages 列表。回头看第 3 章的 create_subagent 函数——每次调用都 messages = [{"role": "user", "content": task}],这就是上下文隔离。
坑 3:工具描述太模糊
工具的描述决定了 Agent 能不能正确使用它。描述写得模糊,Agent 就不知道什么时候该用、怎么用。
| 做法 |
效果 |
"description": "搜索" |
Agent 不知道搜什么、返回什么格式 |
"description": "搜索互联网获取产品信息、评价和定价数据。输入搜索关键词,返回相关结果摘要。" |
Agent 清楚知道工具能力和适用场景 |
工具设计三条规则:
- 描述写清楚:说明输入什么、返回什么、什么场景下用
- 功能要专一:一个工具做一件事,别搞"万能工具"
- 参数要约束:用 JSON Schema 的
required 和类型限制
坑 4:调试困难
多 Agent 系统最大的问题不是搭建,而是出了 bug 很难定位。多个 Agent 并行运行,某个给了奇怪的结果——你怎么知道是哪个 Agent 的问题?
我的经验是三个方法最管用:
- 打日志 —— 记录每个 Agent 的输入和输出,出问题时能回溯。
1
2
3
4
5
6
7
8
9
10
|
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger("agent")
def create_subagent(role: str, task: str, tools: list = None) -> str:
logger.info(f"[启动] 角色={role[:50]}... 任务={task[:80]}...")
# ... Agent 逻辑 ...
logger.info(f"[完成] 结果={result[:200]}...")
return result
|
-
开发时关掉并行 —— 让 Agent 一个个跑,方便定位。上线后再开并行。
-
设置 temperature=0 —— 让结果尽量可复现。
坑 5:Prompt 越堆越长
随着系统变复杂,你可能会不断给 Agent 加指令。Prompt 越来越长,Agent 反而越来越笨——因为注意力被分散了。
解法: 把复杂指令拆到多个专门的 Agent 里,而不是全塞到一个 Prompt。这也是多 Agent 架构的核心价值之一:通过分工降低单个 Agent 的认知负担。
你只需要知道:多 Agent 的主要成本是 Token。保持上下文隔离、写好工具描述、打好日志,能避开大部分坑。
6. 接下来做什么
到这里,你已经掌握了多 Agent 系统的核心:
- ReAct 循环让 Agent 能自主推理和行动
- 编排器-子 Agent 架构让多个 Agent 分工协作
- 上下文隔离保证了每个 Agent 的工作质量
- Token 消耗和调试是实际落地时要重点关注的
如果你想继续深入,可以看看这几个方向:
- 接入真实搜索 API:把模拟搜索换成 Tavily 或 SerpAPI,让系统能真正上网搜信息
- MCP 协议:标准化的 AI 工具集成方案。CNCF 在 KubeCon 2026 首次设立了 Agentics Day,云原生和 Agent 系统正在快速融合
- Anthropic Agent SDK:官方的 Agent 开发工具包,封装了本文手写的很多逻辑,适合生产环境
- 生产级部署:认证管理、速率限制、错误重试、成本监控——从 demo 到生产还有不少路要走
本文的代码基于 anthropic Python SDK,模型使用 claude-sonnet-4-20250514(Claude Sonnet 4)。代码结构经过简化以突出核心概念,实际项目中需要补充错误处理、重试逻辑和日志。
多 Agent 系统是个强大的工具,但不是银弹。简单任务用单 Agent 就够了。只有当任务真的需要多种专业能力协作,或者能拆成独立子任务并行处理时,多 Agent 架构才值得上。
