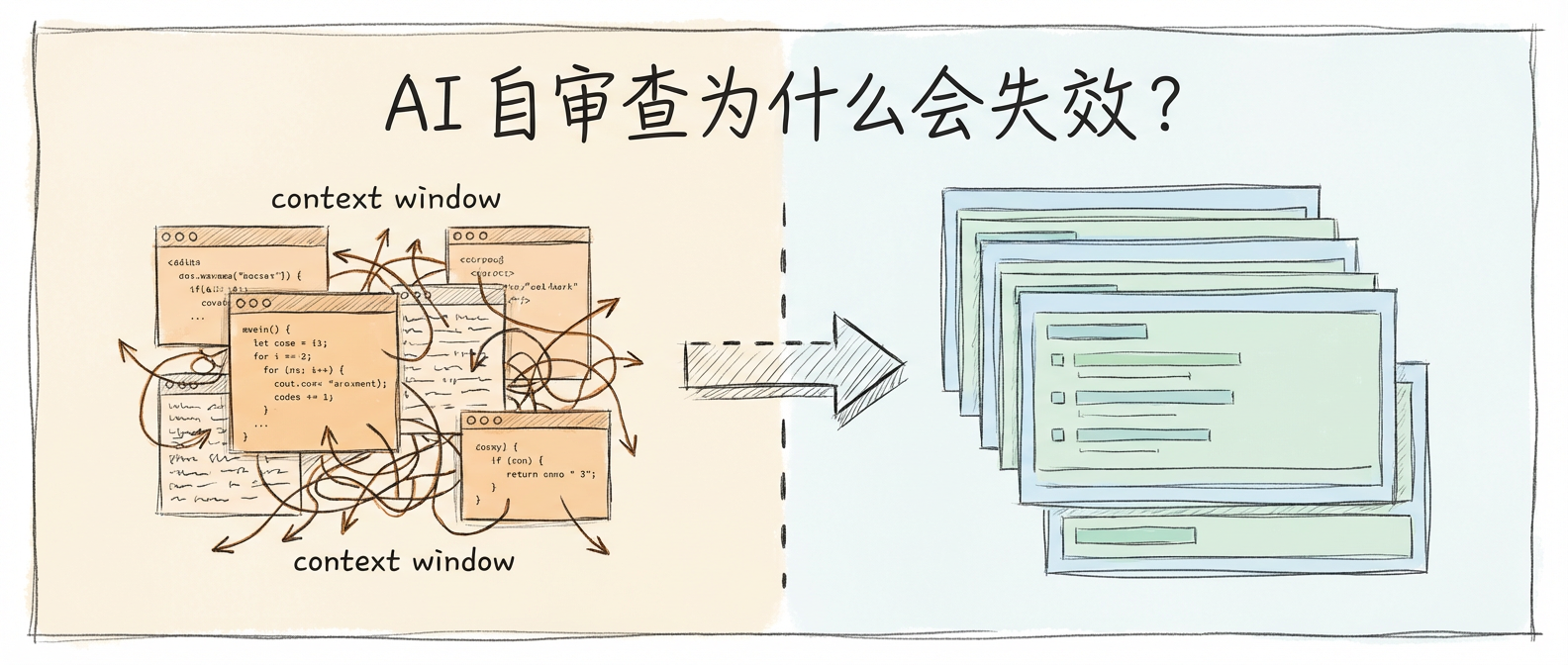
你有没有遇到过这种情况:让 AI 写了一段代码,再让它检查一遍,结果它对明显的边界条件错误视而不见。
明明同样的模型,在审查别人的代码时能挑出一堆问题,审查自己的输出时却像"瞎了"一样。
这不是 AI 不够聪明。问题出在它的"视野"——当它生成完内容后再审查,评判标准已经被自己写的东西挤到了角落。
一、AI 的"视野"被占满了
位置偏见:信息在哪儿很重要
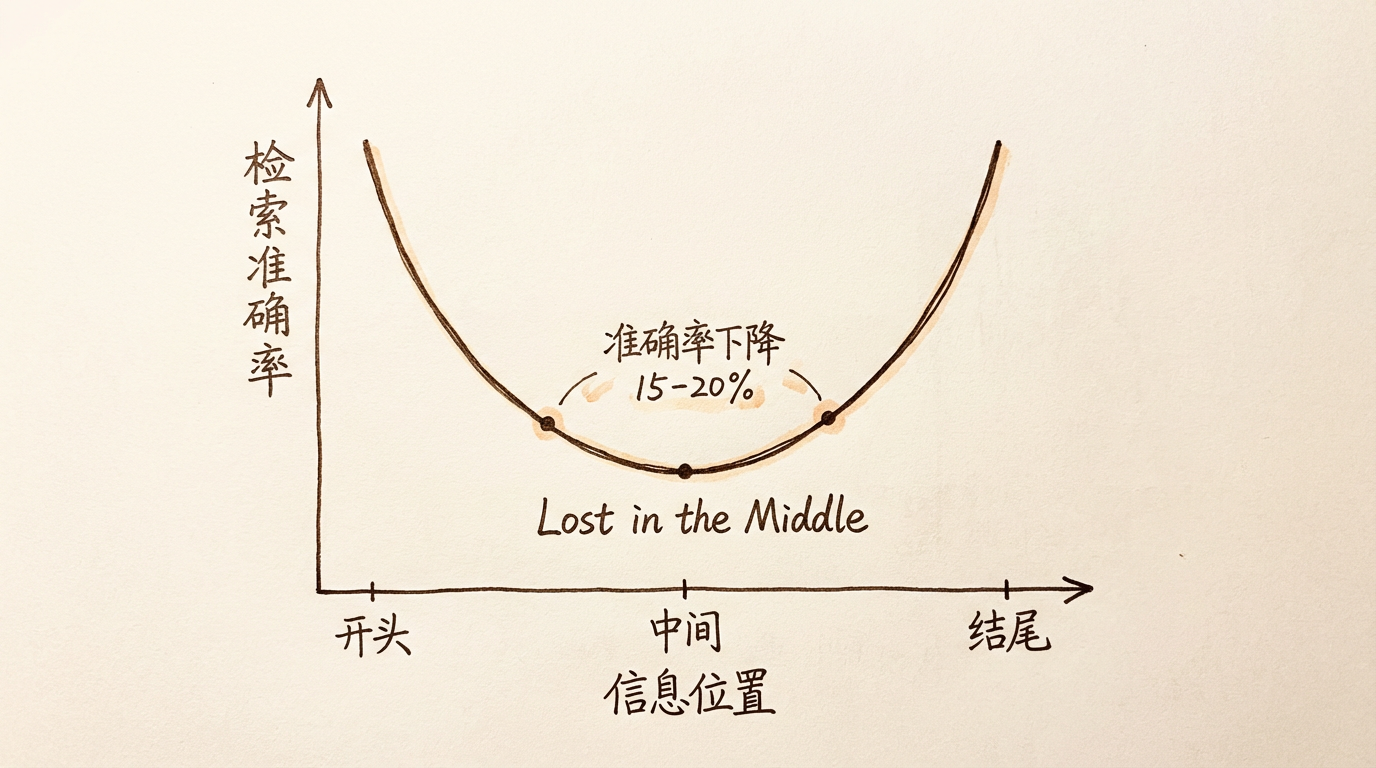
2023 年,一篇叫"Lost in the Middle"的论文揭示了一个现象:大模型检索信息的能力,取决于信息在上下文中的位置。
研究者做了一个实验:把一段需要回答的信息放在上下文的不同位置,让模型找出来。结果是 U 型曲线——信息在开头或结尾时,模型表现最好;在中间时,表现明显下降。
数据很具体:从位置 1 到位置 10,准确率下降 15-20%(Redis Blog)。
这跟人类很像。你读一篇长文章,开头和结尾记得最清楚,中间的内容容易模糊。但 AI 的问题更严重——它的"有效视野"是硬约束,不像人类可以回过头重读。
自审查时的"视野"问题
现在回到自审查的场景。
你的 Prompt 开头写着"请检查以下代码,确保没有边界条件错误、空指针问题"——这些是评判标准。
AI 开始生成代码,写了几百行。
现在你让它审查。问题来了:评判标准(原本在上下文开头)已经被它生成的代码挤到了中间位置。
就像让学生写完一篇长作文后立即批改自己的卷子——作文已经占满了他的"视野",评分标准被挤到了角落。他能看到的只有自己刚写的内容。
Context Rot:长上下文不等于好上下文
很多人有个误解:上下文窗口越长越好。反正能塞进去,塞就是了。
但"Lost in the Middle"告诉我们:问题不是容量不够,而是"有效视野"被挤占。长上下文不等于好上下文。当重要信息被挤到中间位置,模型就会"看不见"它。
所以,自审查失效的根因不是模型能力不足,而是架构设计有问题:把"生成"和"审查"塞进了同一个上下文窗口。
二、一次推理只做一件事
Constitutional AI 的启示
Anthropic 在训练 Claude 时,需要让模型学会自我审查。他们是怎么做的?
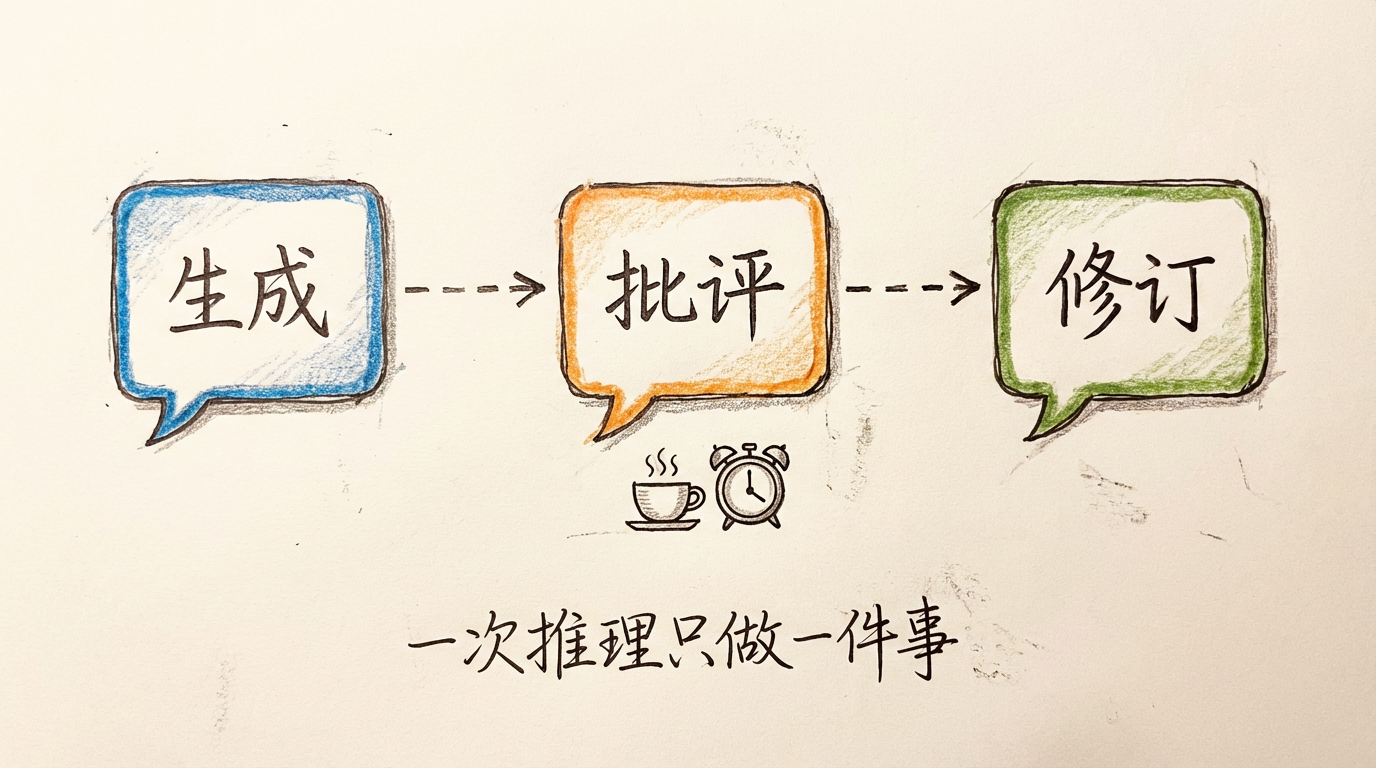
分阶段执行:先生成内容,再生成批评,最后生成修订版本。这三个步骤不是在一次推理调用中完成的,而是三次独立的调用。
关键洞察:批评需要独立的推理空间。
想象一下,你在写作文。写完初稿后,你会怎么做?如果立即修改,效果往往不好——你的注意力还在"刚才写了什么"上。更好的做法是放一放,过一会再回头看。这时候你才能真正以"审阅者"的视角审视自己的作品。
Constitutional AI 的设计哲学就是:让批评在"冷静"的状态下进行——独立的推理空间。
RLAIF 的验证:评价者必须独立
RLAIF(AI 反馈强化学习)的研究进一步验证了这个原则。
研究者发现:AI 可以评价 AI 的输出,但评价者与生成者必须是不同的实例。当评价者只看到输出,不参与生成过程时,它的判断与人类评价者的一致性达到 78%——接近人类之间的评价一致性(73-77%)。
这证明了一件事:AI 有能力评价 AI 输出,前提是评价者要"独立"——不被生成过程的上下文污染。
还有一个意外发现:Self-Consistency(让模型对同一问题生成多个答案,取多数投票)反而降低了准确性超过 5%(RLAIF 论文)。
直觉上,“多想几遍"应该更准确。但数据告诉我们:在同一个上下文中反复思考,不会产生新的视角,只会放大已有的偏见。
核心原则
综合这些发现,可以提炼出一个设计原则:
一次推理只做一件事。
批评和修订是独立的认知任务,不应该塞进同一个上下文窗口。就像考试时,答题和阅卷是两件事;写作时,写初稿和改稿是两件事。
这不是什么高级技巧,而是绕过 LLM 认知限制的架构设计。
三、多 Agent 架构:上下文隔离的工程实现
为什么需要多 Agent
单 Agent 的问题很清楚:上下文窗口会被累积的任务信息占满。当任务复杂、对话变长,有效视野就会被稀释。
多 Agent 架构的核心价值不是什么高级,而是上下文隔离。
就像操作系统的进程隔离——一个程序崩溃不会影响其他程序。每个 Agent 有独立的上下文窗口,不会被其他任务的上下文污染。
四种模式对比
实践中,多 Agent 有几种常见的架构模式:
| 模式 | 上下文隔离程度 | 适用场景 |
|---|---|---|
| Subagents | 强隔离 | 自审查、独立任务 |
| Skills | 弱隔离 | 能力扩展、工具调用 |
| Handoffs | 显式传递 | 流水线式任务 |
| Router | 天然隔离 | 多入口分发 |
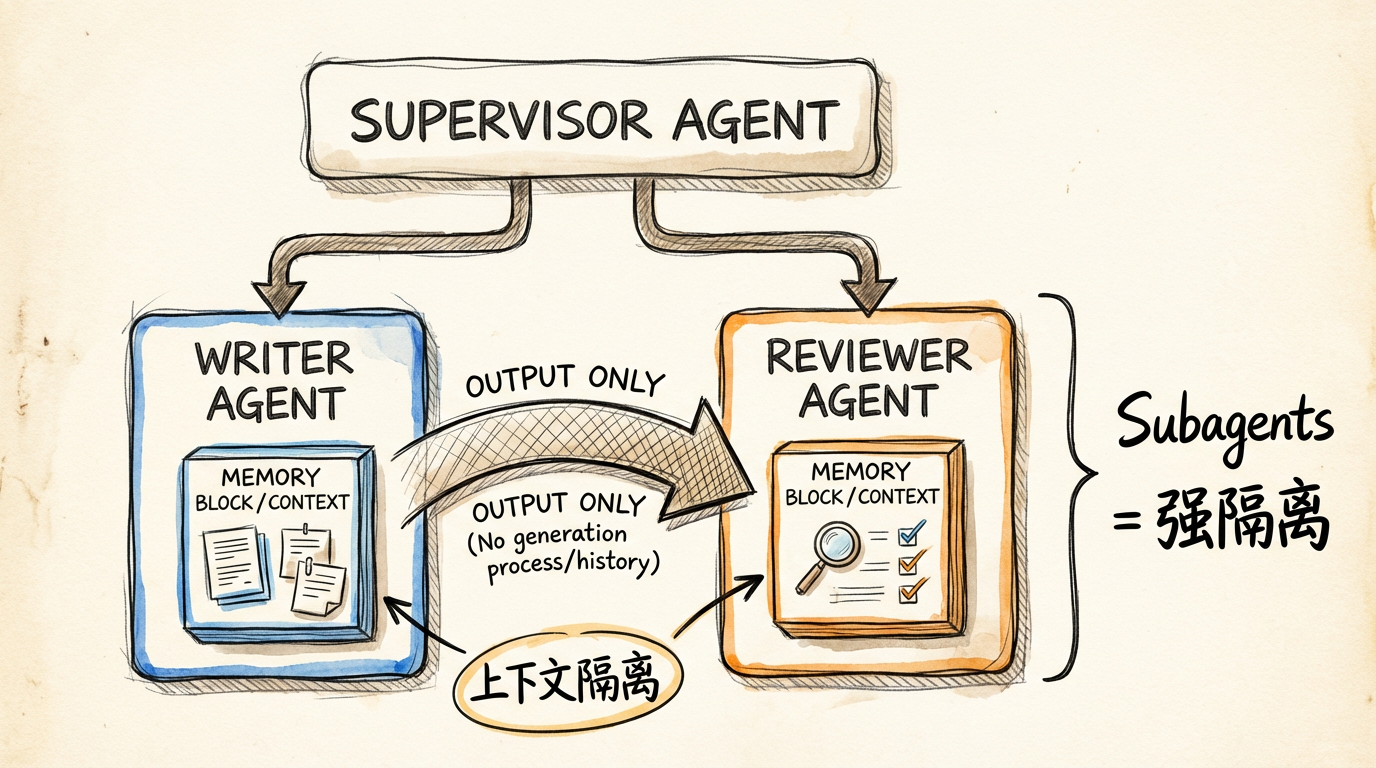
Subagents 的隔离程度最高:主 Agent 维护对话上下文,子 Agent 作为"工具"被调用。子 Agent 只看到必要的历史信息,不会被主上下文污染。
为什么 Subagents 最适合自审查
回到自审查的场景。
假设你要实现"AI 写代码,AI 审代码"的流程。用 Subagents 模式,可以这样设计:
- Writer Agent:接收任务,生成代码,输出结果
- Reviewer Agent:只接收 Writer 的输出,不参与生成过程
Reviewer Agent 的上下文窗口里只有:评判标准 + 待审查的代码。它不会看到 Writer 的思考过程、中间尝试、错误修正——这些"历史包袱"与审查任务无关,只会挤占有效视野。
这就像工厂的流水线:焊接工人不负责质检,质检工人不负责焊接。不是焊工不够专业,而是"自己检查自己的焊缝"这个流程本身就有盲区。
实践建议
设计一个自审查系统,记住这几条:
- 审查 Agent 只接收输出,不参与生成过程
- 用状态和契约决定下一步,而不是"靠模型自己悟”
- 每个 Agent 只做一件事,上下文窗口只保留必要信息
第三条最重要。设计 Agent 时容易犯的错误是:把所有"可能有用的信息"都塞进上下文。这是错的。信息越多,有效视野越容易被稀释。
把"靠模型自己从上下文里悟出来该做什么"变成"靠状态与契约决定下一步,靠工具做确定性动作"。这才是可调试的 Agent 系统设计。
结语:不是 AI 不够聪明
AI 自审查失效,不是因为模型不够聪明。
位置偏见是 LLM 的固有特性——信息在上下文中的位置影响检索能力。这不是 bug,是架构约束。你没法通过"更聪明的模型"解决它。
真正的解决方案是工程架构:让不同的推理任务在独立的上下文空间中执行。
这个设计哲学的应用场景很广:
- 代码审查 → 独立的审查 Agent
- 文章校对 → 独立的编辑 Agent
- 任何需要"反思"的场景 → 分离上下文
Agent 系统的最大敌人不是 LLM 的能力,而是不可调试性。当系统出问题时,你能追溯每个 Agent 看到了什么、做了什么决策,这才是可控的 AI 系统。
分离上下文窗口,是为了可靠。