
系列第三篇 · 行业视角 · 预计阅读 15 分钟
周一早上,你打开维护了三年的开源项目,发现周末多了 17 个 Pull Request(合并请求,简称 PR)。你开始逐个审查——代码风格统一、测试齐全、提交说明规范。直到你注意到,这 17 个 PR 来自同一个账号,一个你从没在社区见过的名字。
你点进他的 profile:注册 3 天,已经给 40 个项目提了 PR。
这不是一个勤奋的新人。这是一个 Coding Agent。
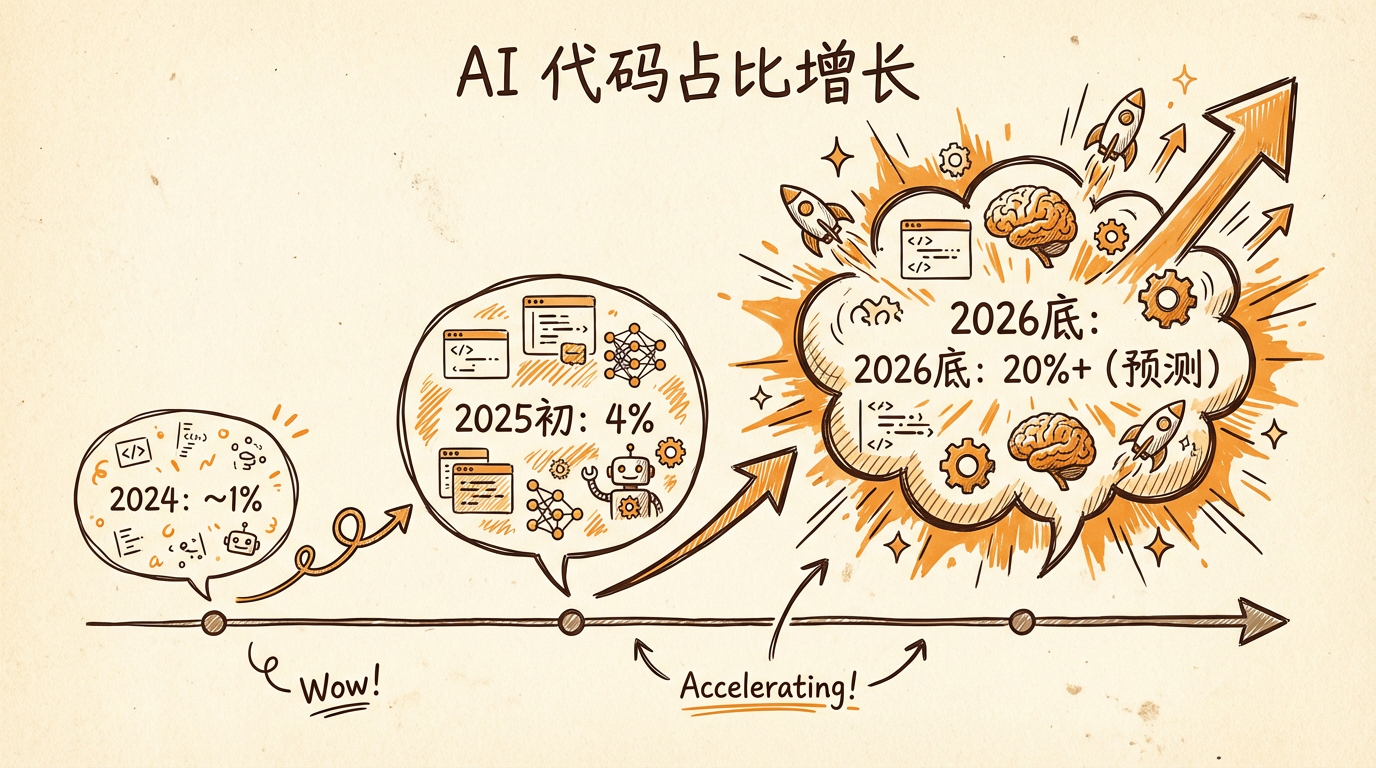
这个场景不是科幻。SemiAnalysis 的数据显示,仅 Claude Code 一个工具,每天就产生约 13.5 万次 GitHub 提交,占所有公开提交的 4%。算上其他 AI 编程工具,这个比例只会更高。到 2026 年底,AI 生成的代码占比预计会突破 20%。
这篇文章聊三件事:AI 代码已经做到了什么,带来了哪些麻烦,以及我们该怎么应对。
一、惊艳的一面:AI 真能写出好代码
先看一个让人服气的案例。
Hugging Face 团队做了一个实验:让 AI Agent(Claude 和 Codex)写 CUDA 内核。简单说,CUDA 内核是让程序直接跑在 GPU 上的底层代码,性能要求极高,通常只有少数专家能写好。
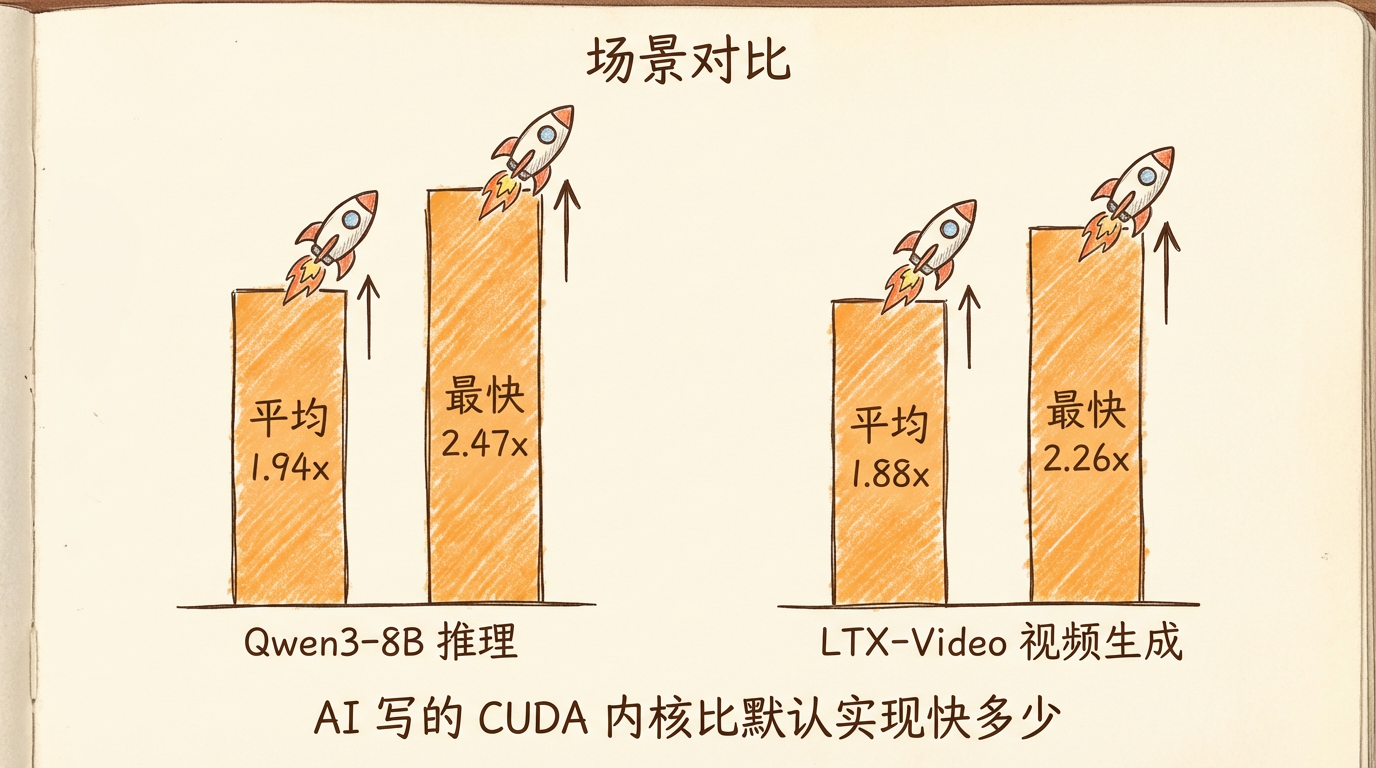
结果出人意料。AI 写的内核在 NVIDIA H100 GPU 上跑出了这样的成绩:
| 场景 | 比默认实现快多少(平均) | 最快能快多少 |
|---|---|---|
| Qwen3-8B 推理 | 1.94 倍 | 2.47 倍 |
| LTX-Video 视频生成 | 1.88 倍 | 2.26 倍 |
而且数据量越大,优势越明显——128 tokens 时快 1.58 倍,8192 tokens 时快 2.47 倍。
这不是实验室 demo。这些内核已经跑在 Hugging Face 的 transformers 和 diffusers 库里,服务真实的生产流量。当然,这是精心调试的结果,不是每次 AI 生成的代码都能达到这个水准——但它证明了 AI 代码的能力上限。
你只需要知道:AI 已经能写出超越 PyTorch 默认实现的 GPU 底层代码,而且是生产级别的。
二、全面渗透:AI 代码的规模有多大
Hugging Face 的案例只是冰山一角。
OpenClaw——一个 2025 年 11 月才诞生的项目,4 个月内在 GitHub 上狂揽 25 万星标,超越了积累十多年的 React 和 Linux。它的代码库据报道接近 100% 由 AI Coding Agent 编写,从 README 到项目结构,从核心逻辑到测试用例,全部由 AI 在极短时间内生成。
这不是个例。看全局数据:
- 4%:仅 Claude Code 一个工具产生的 GitHub 公开提交占比(SemiAnalysis 数据)
- 20%+:SemiAnalysis 对 2026 年底 AI 代码占比的预测
- 25%:谷歌内部新代码中 AI 生成的比例(Sundar Pichai,2024 Q3 财报电话会)
- 30%:GitHub 此前披露的内部使用 Copilot 完成代码的比例
数字已经摆在这了。AI 代码早就不是"即将到来"的事。
但数字只是一面。这些代码进入开源生态后,引发了一堆过去不存在的问题。
你只需要知道:AI 代码已经大规模进入开源项目,占比从 4% 快速增长,年底可能达到 20%。不是预测,是正在发生的事。
三、麻烦来了:识别、质量、归属
想象一个社区图书馆。任何人都可以往书架上放书,维护者负责把关质量。突然出现大量匿名投稿——内容看起来不错,但你不知道作者是谁、参考了什么资料、有没有版权问题。
开源项目现在面对的,就是这个局面。
3.1 识别问题:谁在敲键盘?
AI 生成的代码没有水印,长得和人写的差不多。这带来一个实际问题:维护者很难区分一个 PR 是人写的还是 AI 生成的。
有人觉得无所谓——好代码就是好代码,管它谁写的?
但事情没那么简单。Go 语言核心团队在 2026 年 2 月的公开讨论中亮出了他们的态度:拒绝 AI 署名。
事情的起因是一个开发者提交了一个变更列表,在描述里写了:
|
|
Go 创始人 Rob Pike 的回应直截了当:
“这是一个非常危险的滑坡。我建议第一步简单点:说不。”
Go 团队在讨论中形成了清晰的"三不"立场:
- 不接受 AI 共同署名——AI 没有法律主体资格
- 不接受"无人负责"的代码——提交者必须对代码负全责
- 作者列表只属于人类——AI 是工具,不是作者
Russ Cox(Go 前技术负责人)的一段话(译自邮件列表讨论),我觉得比任何分析文章都精准:
“AI 工具诱使许多人陷入一种虚假的信念……人们以前所未有的速度生成大量的代码……就像看着会跳舞的大象,虽然令人惊叹,但通常既慢又笨拙,且难以维护。”
3.2 质量问题:好看不一定好用
AI 生成的代码有一个特点:表面质量很高。格式规范、命名合理、甚至自带注释。但这种"好看"可能掩盖了深层问题。
| 隐患 | 为什么危险 |
|---|---|
| 测试覆盖不足 | 生成了代码但没有充分测试边界情况 |
| “平庸"的实现 | LLM 倾向输出"平均水平"的方案,而不是最优解 |
| 上下文盲区 | AI 不了解项目的整体架构和设计决策 |
| “自信地错误” | 代码能跑但逻辑有微妙错误,比语法错误更难发现 |
Robert Griesemer(Go 创始三巨头之一)提了一个尖锐的问题:
“如果代码描述是 AI 写的,我们可以删掉那行字。但如果是 Claude 写的代码,我们就有大麻烦了。”
这个"大麻烦"指向了一个工程现实:人工 Code Review 有生理极限。当 AI 可以不知疲倦地批量提交 PR,审查速度迟早跟不上生成速度。
3.3 归属问题:这段代码归谁?
这是最棘手的部分。
开源许可证体系——MIT、Apache 2.0、GPL——是为人类贡献者设计的。它们假设:
- 提交者是代码的作者或有权提交
- 作者拥有代码的版权
- 通过许可证授权他人使用
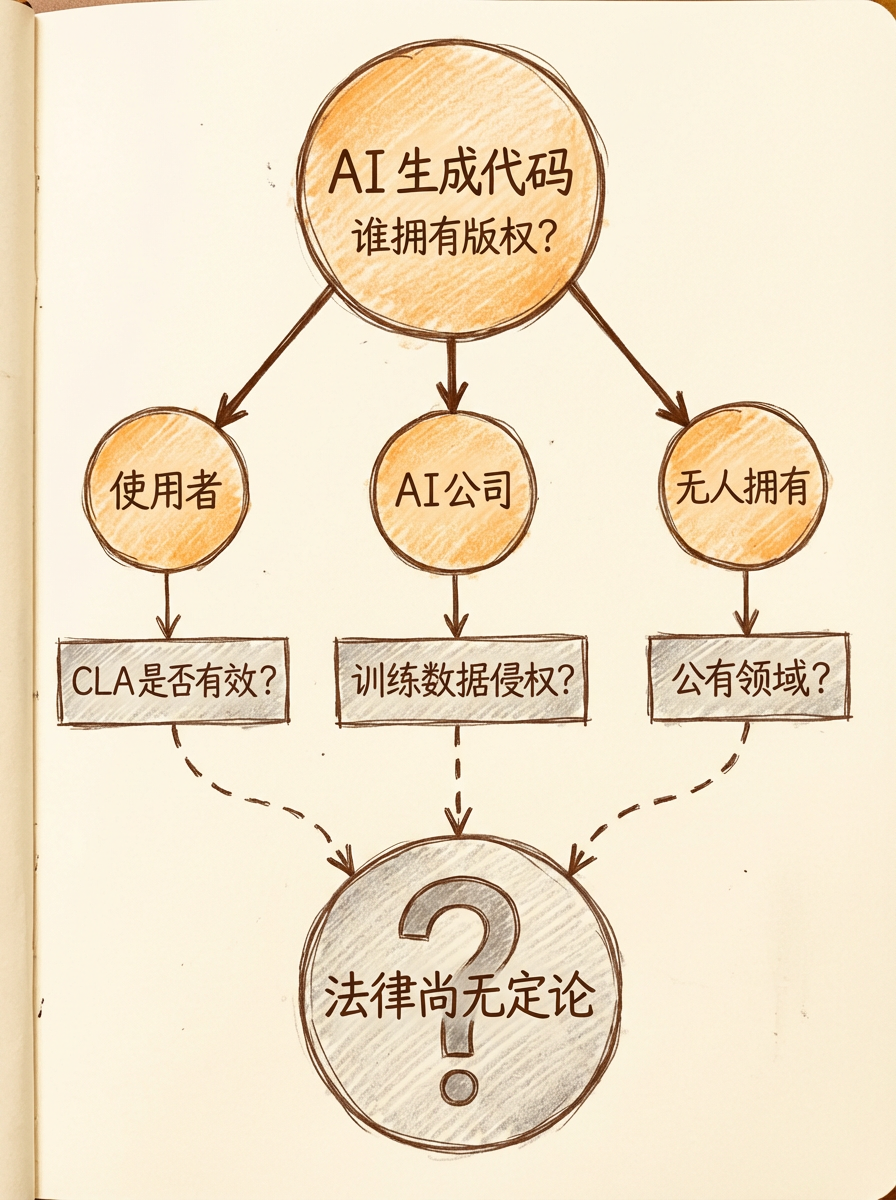
AI 代码打破了这个假设链。
版权问题:美国版权局自 2023 年起持续发布系列报告(已出三部分,最新一部分涉及生成式 AI 训练),正在厘清 AI 生成作品的版权归属。目前的基调是:纯 AI 生成的内容不受版权保护,但人类有实质创意贡献的 AI 辅助作品可能受保护。这个界限还在摸索中。
CLA(贡献者许可协议)失效风险:很多开源项目要求贡献者签 CLA,前提是贡献者拥有代码版权。如果 AI 是实际编写者,这份 CLA 的法律效力存疑。
训练数据的坑:如果 AI 记住了 GPL 协议的代码并"吐"出来,合入 BSD 协议的项目——这是一个假设性但不可忽视的风险,目前还没有判例。
你只需要知道:AI 代码带来了三重挑战——难以识别、质量参差、法律灰色地带。这不是技术问题,是治理问题。
四、角色转变:从"写代码"到"定标准”
聊完了问题,该聊怎么适应了。
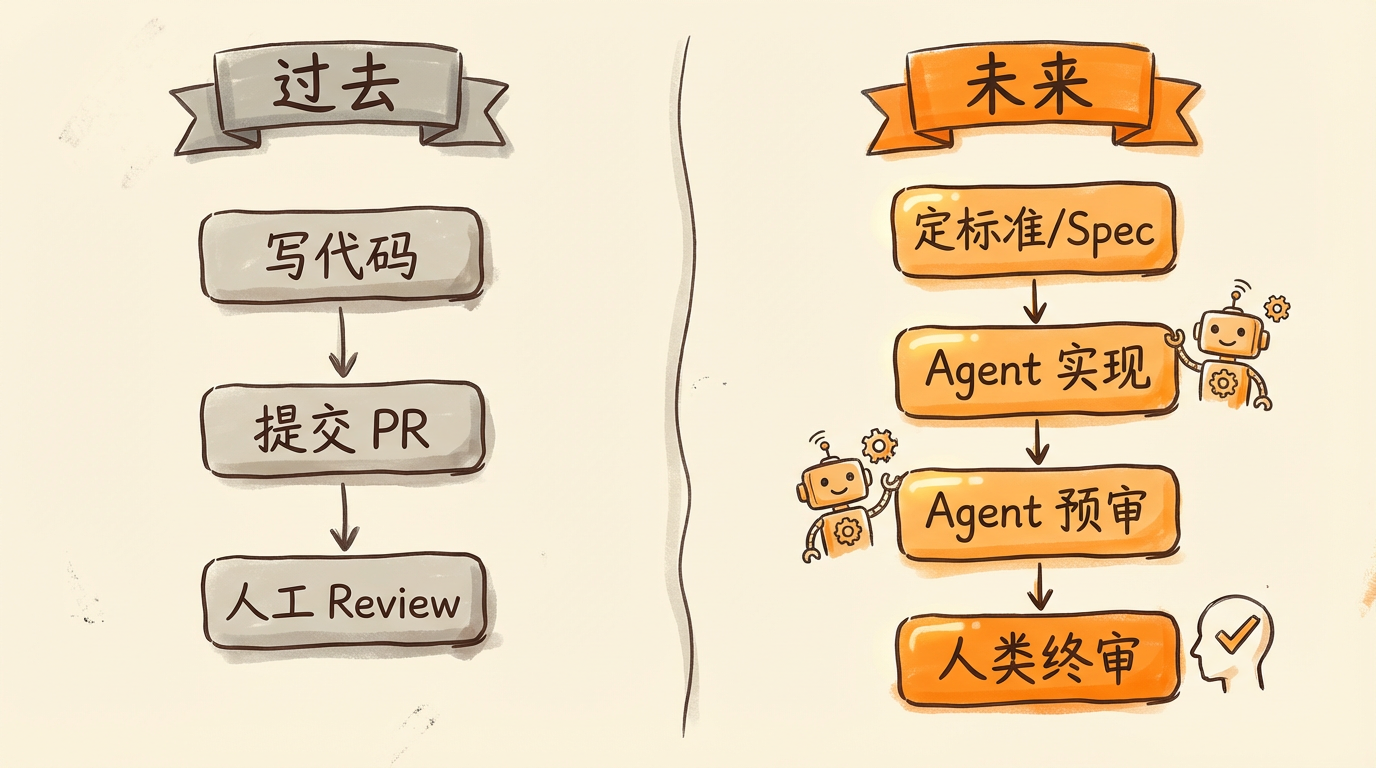
维护者:从代码审查者变成标准制定者
过去,维护者的核心工作是审查代码质量。现在和未来,更重要的工作是定义蓝图和标准。
Tony Bai 在分析中总结得很到位:
“不再:亲自写代码、亲自 Review 每一行代码。而是:定义蓝图、设定标准、在机器迷失方向时握住方向盘。”
已经有项目在讨论引入"守门员 Agent"——一个前置的 AI 审查系统,负责跑测试、检查代码风格、做基本的逻辑推理。只有通过 Agent 预审的 PR,才会到人类维护者面前。
贡献者:从提交代码变成提交 Spec
当代码变得廉价,真正有价值的是意图和约束。
未来的开源贡献可能不是提交一段代码,而是提交一份 Spec(规格说明)或 Test Case。你描述"这个功能应该做什么",AI 负责实现。你的贡献在于定义问题,而不是编写答案。
这听起来有点激进,但想想 OpenClaw——项目的全部代码由 AI 生成,人类的贡献在于方向决策、架构设计和质量标准。
声誉重构:Commit 数不再等于能力
GitHub 的绿色贡献图表可能要贬值了。当一个人可以用 Agent 在一天内给 40 个项目提 PR,“提交数量"失去了衡量能力的意义。
未来的声誉体系可能需要新的维度:
- PR 通过率(而不是提交数)
- 下游引用量(你的 Spec 被多少项目采用)
- 代码存活率(提交的代码一年后还在不在)
你只需要知道:维护者从"审代码"变成"定标准”,贡献者从"写代码"变成"写 Spec",声誉从"数量"变成"质量"。
五、悬而未决的问题
到这里,该讲的都讲得差不多了。但有些问题,我也给不出好的答案。坦诚说几个——不是因为不重要,恰恰是因为太重要了,值得单独拎出来。
许可证体系的更新
现有的开源许可证是 20 年前的产物。它们没有考虑过"AI 生成代码"这个变量。
谁来推动更新?目前没有共识。OSI(Open Source Initiative)在 2024 年发布了 OSAID 1.0(开源 AI 定义),但聚焦点是"什么算开源 AI 模型",而非"AI 生成的代码贡献如何归属"。FSF(自由软件基金会)尚未就此发表明确立场。也就是说,最需要回答的问题——AI 代码的版权和许可证归属——目前没有任何权威机构在正面回应。
开源精神是否会变质
开源的核心精神是"共享智慧"。如果贡献变成了"让 AI 刷量",这种精神还在吗?
乐观的看法是:开源的本质不是共享代码(代码越来越廉价),而是共享知识——架构模式、设计决策、最佳实践。AI 反而让这种本质更加凸显。
但也有人担心:当通用工具库可以被 AI 随时生成,大量 Utils/Helpers 类库可能消亡。有些人管这叫"即时软件"——用的时候现场生成,比搜索安装省事。这不是共识,但值得关注。
平台的进化
GitHub 这样的平台也需要跟上。可能的方向:
- AI 预审开关:仓库设置里一键开启 Agent 预审
- 意图搜索:从关键词搜索进化到"我想解决 X 问题"的语义搜索
- AI 来源标记:自动检测并标记 AI 生成的 PR
但什么时候落地?不知道。

你只需要知道:许可证、开源精神、平台能力——都在变,但没有现成答案。这些问题的走向,会决定开源的下一个十年。
写在最后
回到开头的场景:你的项目周末多了 17 个来自 Agent 的 PR。
你可以恐慌。你也可以兴奋。但更有用的态度是清醒。
AI 代码进入开源是一个事实。一个需要新规则和新工具来应对的事实。
几件现在可以做的事:
- 给你的项目定一个 AI 贡献政策——Go 团队已经做了,你也可以。不需要很复杂,明确"AI 辅助的代码谁负责"就是一个好的开始
- 引入自动化预审——CI/CD 流水线里加上基本的代码质量检查,减轻人工审查压力
- 关注贡献质量而非数量——调整你评估贡献者的标准
- 参与社区讨论——关注你所在语言社区(如 Go 的 golang-dev 邮件列表)或 OSI 的 AI 相关工作组,这些规则的制定需要一线维护者的声音
Rob Pike 说得好:
“我建议第一步简单点:说不。”
在还没想清楚之前,“说不"可能比"全盘接受"更明智。但长远来看,开源社区需要的不是拒绝,而是一套新的规则。
这套规则还在形成中。你可以成为制定者之一。
参考资料
- AI时代的开源:当Coding Agent接管GitHub — Tony Bai 对 AI 代码进入开源生态的全景分析
- Go 核心团队拒绝 AI 署名 — Go 团队关于 AI 代码归属的政策讨论
- Custom CUDA Kernels: Agent Skills — Hugging Face AI 生成 CUDA 内核的完整实验报告
- 谷歌 AI 代码占比 — Sundar Pichai 在 2024 Q3 财报中披露谷歌 25% 新代码由 AI 生成
- Copyright and Artificial Intelligence — 美国版权局 AI 与版权系列报告
- Open Source AI Definition (OSAID) — OSI 对开源 AI 的定义和 FAQ
本文是"AI 时代工程师进化"系列的第三篇。
- 第一篇:《停止「氛围编程」》——问题诊断 + 价值主张
- 第二篇:《Agentic Engineering Patterns》——实操方法 + 工程实践
- 第三篇:《AI 重塑开源》——生态影响 + 未来趋势(本文)