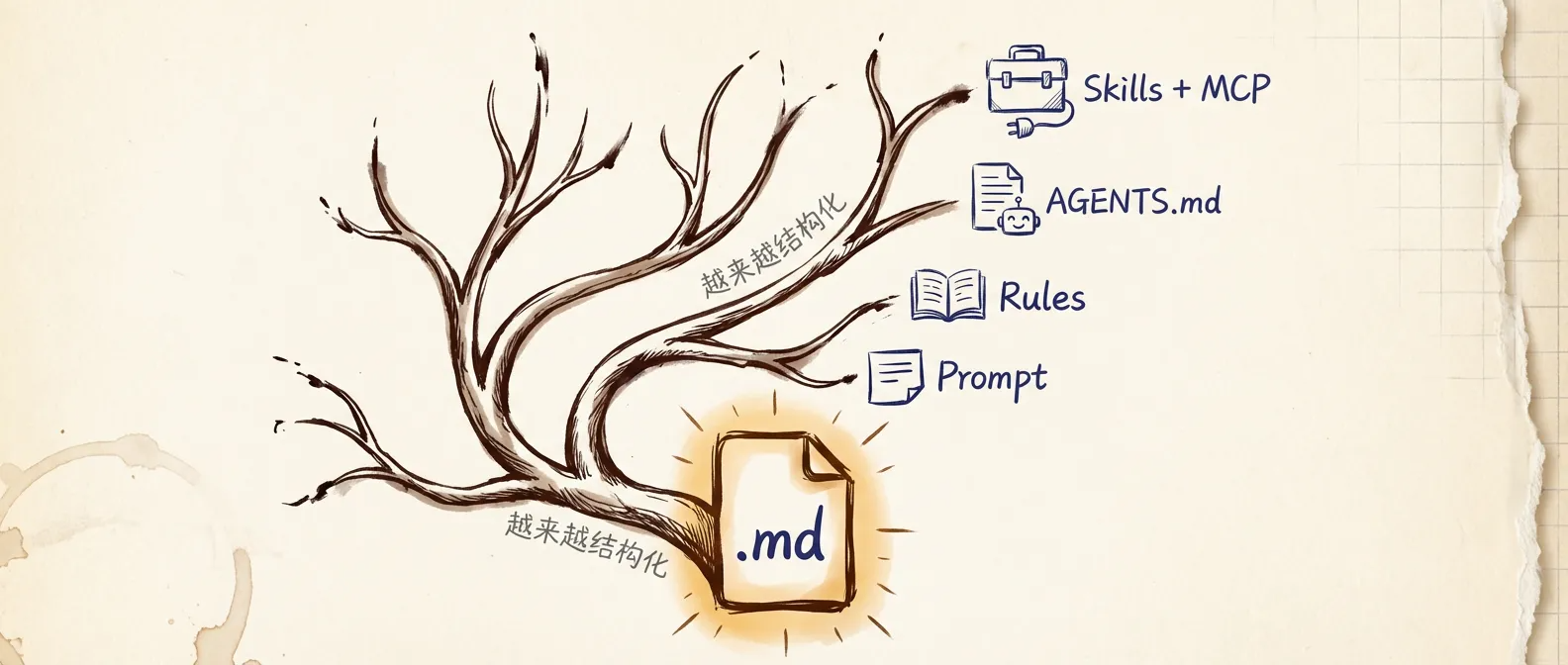
你还记得第一次给 AI 写 prompt 的样子吗?
我记得。2025 年的某个深夜,我对着 ChatGPT 的输入框,像写第一封求职信一样字斟句酌。“请用专业但友好的语气”、“请确保代码有注释”、“请不要使用已废弃的 API”——每一条都是从上次踩坑里学来的教训。
写了二十几次之后,我发现一个尴尬的事实:我每次开新对话,都在重复同样的话。
这就像每天上班都要重新自我介绍一遍。
从那时候起,AI 的"配置文件"开始了一场安静的进化。从一句话到一整个文件夹,这条路走得比多数人意识到的要远得多。
便利贴时代:Prompt
System Prompt 是最原始的配置方式。你在对话开头塞一段话,告诉 AI 它是谁、该怎么说话、有什么禁忌。
好用吗?好用。但有三个硬伤。
会话一关,什么都没了。 下次开聊,你得把那段话再贴一遍。Prompt 就是便利贴——写了就贴上,但贴多了桌面就乱了,而且风一吹就掉。
上下文窗口是有限的。 哪怕现在有些模型号称百万 Token 上下文,你也不会因为冰箱大了就把所有食材一股脑塞进去——找不到的东西等于没有。塞的 prompt 越长,噪声越多,AI 反而更容易走神。
没法按项目区分。 写前端代码和写后端代码需要完全不同的 prompt,但你没有地方管理这些区别。
于是有人想到——把便利贴钉成一本手册。

员工手册时代:Rules
.cursorrules、rules.md、.claude 这些文件的出现,解决了持久化问题。你把规则写进文件,扔到项目根目录,AI 每次启动都会读。
这一步的进化很实在:规则不再随会话消失,而是跟着项目走。
但 ETH Zurich 的一项研究揭示了一个反直觉的事实:不是所有规则都有用。
研究团队在 SWE-bench 和 AGENTbench(两个评估 AI 编码能力的标准测试集)上测试了上下文文件的效果。结果是——
人工精心编写的规则文件,平均提升任务完成率 +4%。 LLM 自动生成的规则文件,反而让完成率下降了 0.5%-2%。
差距从哪来的?人类工程师知道 AI 会在哪里犯错,所以写的是防错指南;LLM 不知道,所以写的是百科全书。一个是"别碰那个开关",一个是"这栋楼有 37 层,建于 1998 年"。
这项研究还有一个值得注意的发现:加了上下文文件的 Agent,推理时消耗的 Token 多了 14%-22%,执行步骤多了 2-4 步。信息越多,AI 想得越多,但想多了不等于想对了——和人一样。
手册有了,但手册只能告诉你"公司规定不准迟到"。它不告诉你今天该干什么。

部门章程时代:AGENTS.md
AGENTS.md 做了一件 rules 做不到的事:给 AI 一个身份。
Rules 是规则清单,AGENTS.md 是角色说明书。它告诉 AI——你是谁(“你是一个后端工程师 Agent”)、你有什么工具(“你可以读写文件、运行测试”)、你在什么阶段(“现在是代码审查阶段,不要写新功能”)。
这里有个关键洞察:告诉 AI “不要做什么”,比"这是什么"更管用。
从 ETH Zurich 的那组数据可以推断:人工编写的上下文文件之所以有效,核心原因不是描述了项目全貌,而是精准约束了 AI 的行为边界。“不要修改 X 文件”、“禁止使用 Y 库”——这类限制性指令,比"这是一个 React 项目"这类描述性指令管用得多。
为什么?相比缺什么知识,AI 更常犯的错是不守规矩。
从员工手册升级到部门章程,每个 Agent 有了自己的 JD。但很快你会发现——一个 Agent 能力再强,遇到需要"设计 + 编码 + 测试"协作的任务,它还是捉襟见肘。

工具箱时代:Skills + MCP
Agent 需要工具。但工具得好使。
Skills 是原子化的能力模块——每个 Skill 做一件事,输入输出明确,能独立测试。像标准化工具箱里的螺丝刀和扳手,你拿起来就知道怎么用。
但问题是,Skill 定义写得含糊,AI 就不知道怎么执行。 比如你定义一个 Skill 叫"处理数据",AI 就懵了:处理什么数据?怎么处理?处理完放哪?你给的指令越模糊,AI 越倾向于什么都不做——这不是 Bug,是安全退路。
这和 AGENTS.md 的教训一脉相承:好的 Skill 定义不是描述"这个模块能做什么",而是限制"这个模块只做一件事"。限制越精确,执行越可靠。
工具有了,接口怎么统一?
这就是 MCP(Model Context Protocol)要解决的问题。不同工具由不同人开发,如果每个 Agent 都要单独适配每个工具,那就是 USB-A 到 Lightning 到 Micro-USB 的混乱。MCP 的目标是成为 AI 工具世界的 USB-C——一个协议,所有工具都能插上就用。
到 2026 年,MCP 已经从实验品走向了工程实用。对开发者来说,这意味着你不再需要为每个工具写一套适配代码——插上就能用,就像 USB-C 充电线不挑手机品牌一样。
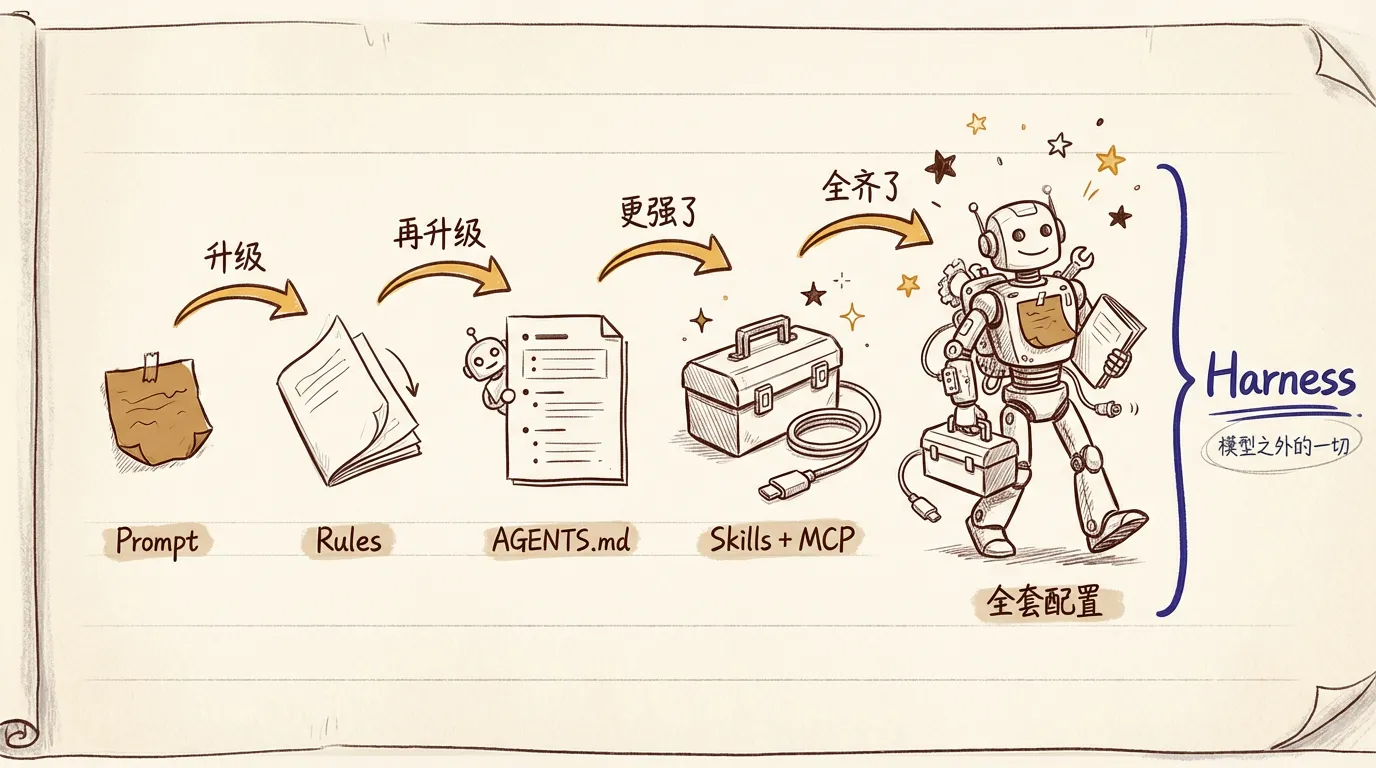
全景图:Harness
回头看这条演进链——prompt → rules → AGENTS.md → Skills + MCP——你会发现一个规律:它们都不是在升级 AI 本身,而是在升级 AI 周围的工程基础设施。
LangChain 给这套东西起了个名字叫 Harness。他们的公式很简洁:
Agent = Model + Harness
Model 是大脑,Harness 是让大脑有用的一切——提示词、工具、文件系统、编排逻辑、状态管理。
这不是学术概念。LangChain 做了个实验:只改 Harness,不换 Model,他们的编码 Agent 在 Terminal Bench 2.0(一个标准编码基准测试)上,从 Top 30 开外跳到了 Top 5。得分从 52.8% 涨到 66.5%。
同一个脑子,换了一副装备,排名蹿了 25 名。
这说明什么?在 AI 时代,“配置工程"比"选哪个模型"更决定最终效果。据我观察,大多数团队花 80% 精力挑模型、20% 精力搭 Harness——但数据告诉你,Harness 的核心不是信息量,是约束精度。精力分配应该反过来。
回到那个 Markdown 文件
从第一次写 prompt 到现在管理一整个 skills/ 目录,变化的不是 AI,是我们和 AI 协作的方式。
每一步升级都不是凭空出现的。Prompt 不够用了才有 rules,rules 太死板了才有 AGENTS.md,单打独斗撑不住了才有 Skills 和 MCP。痛点倒逼进化,每一层都是前一层的补丁。
下一步是什么?说实话我不确定。也许是 AI 自己来管理这些配置文件——但 ETH Zurich 的研究泼了盆冷水:AI 自动生成的规则文件,目前还不如人手写的好使。 机器理解机器,这事比听起来难。
所以至少现在,好好写你的 Markdown 文件吧。毕竟,给 AI 写配置文件这件事,可能是"人类最后的手艺活"之一。