AI 编程工具竞争的胜负手,不在模型——在框架。
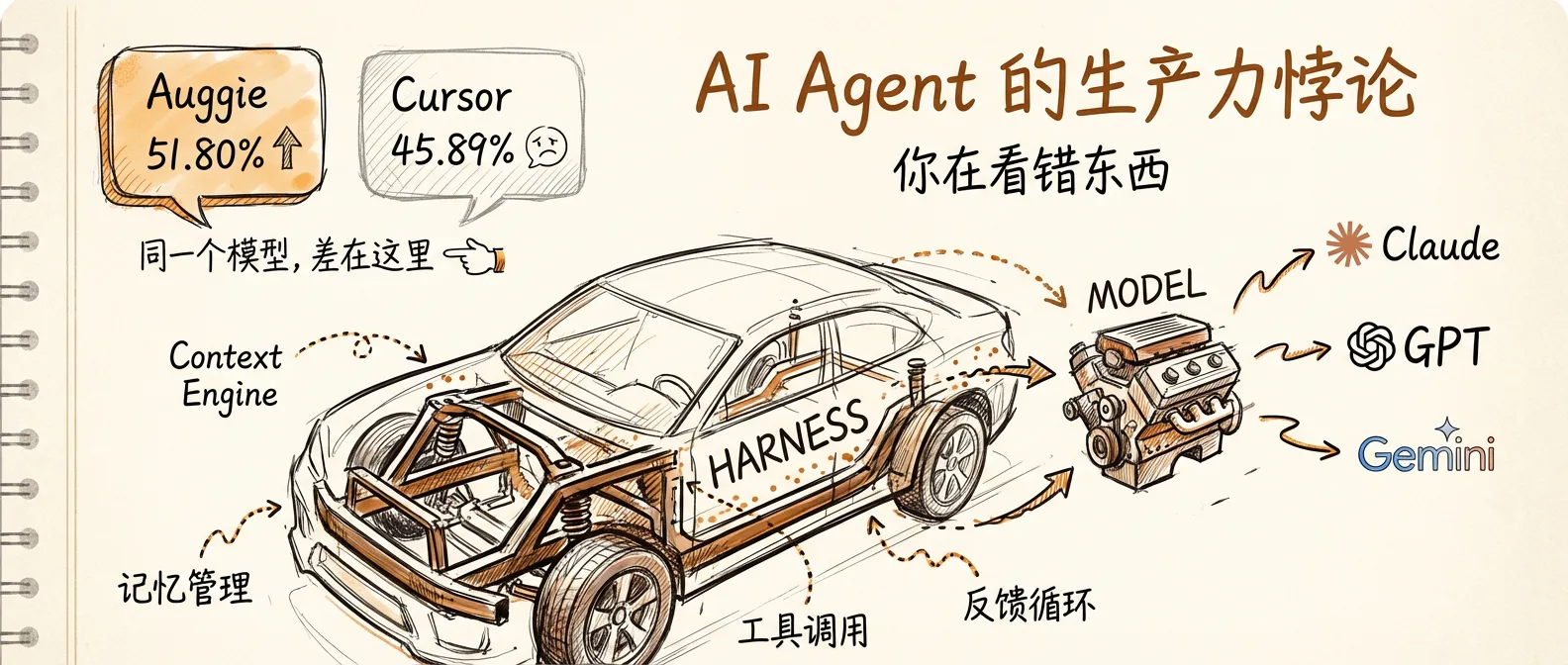
同一模型,6 个百分点的差距
51.80% vs 45.89%。
两个数字来自 SWE-Bench Pro——一个由 Cursor 和 Scale AI 联合推出的编程基准测试,要求 Agent 自主定位真实 GitHub Issue、修改代码、通过测试。Auggie CLI 拿到 51.80%,Cursor 拿到 45.89%。
两者都用的 Claude Opus 4.5(据 Augment Code 博客声明,双方均基于同一底层模型进行测试)。同一个模型,差了 6 个百分点。
差距不来自模型,来自模型之外的东西——Augment Code 团队在博客里把它叫做 Context Engine:一套负责检索代码库、管理上下文、决定"给模型看什么"的工程系统。
这就引出了一个被大多数人忽略的事实:你选 AI 编程工具时,如果只看底层用了 Opus 还是 GPT-5,你在看错东西。

Agent = Model + Harness
LangChain 在一篇博客里给出了一个简洁的公式:
Agent = Model + Harness
Model 是底层大模型——Claude、GPT、Gemini。Harness 是让模型智能变得有用的一切工程基础设施:上下文检索、记忆管理、工具调用编排、错误处理、反馈循环。
打个比方。Model 是发动机,Harness 是底盘。一台 500 马力的发动机放进一辆底盘拉胯的车里,过弯照样甩尾。同理,再强的模型,如果 Harness 喂给它的上下文是错的、工具定义是模糊的、反馈信号是滞后的,输出质量不会好。
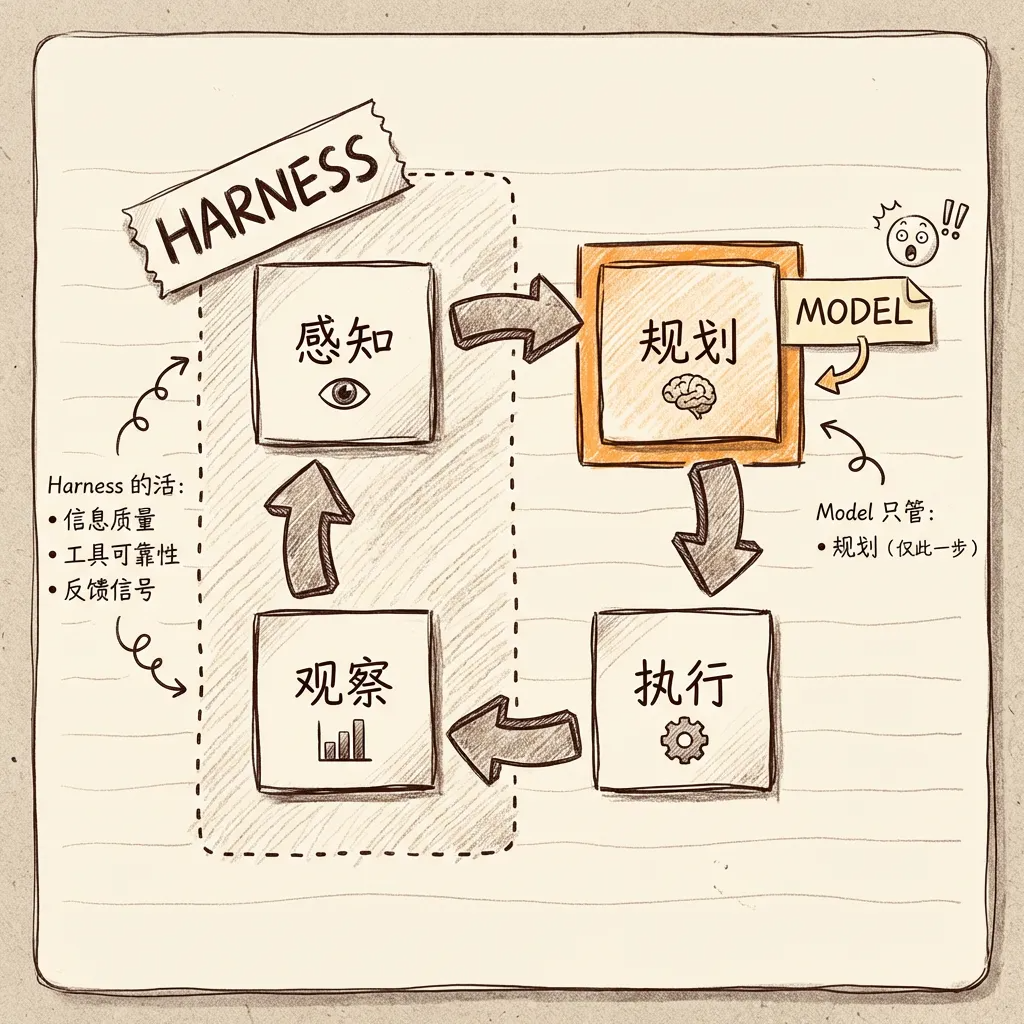
Coding Agent 的工作循环是 感知→规划→执行→观察,持续运转直到任务完成。这个循环里,Model 只负责"规划"这一步——其余三步全是 Harness 的活。感知环节的信息质量、执行环节的工具可靠性、观察环节的反馈信号,全部取决于 Harness 的工程质量。
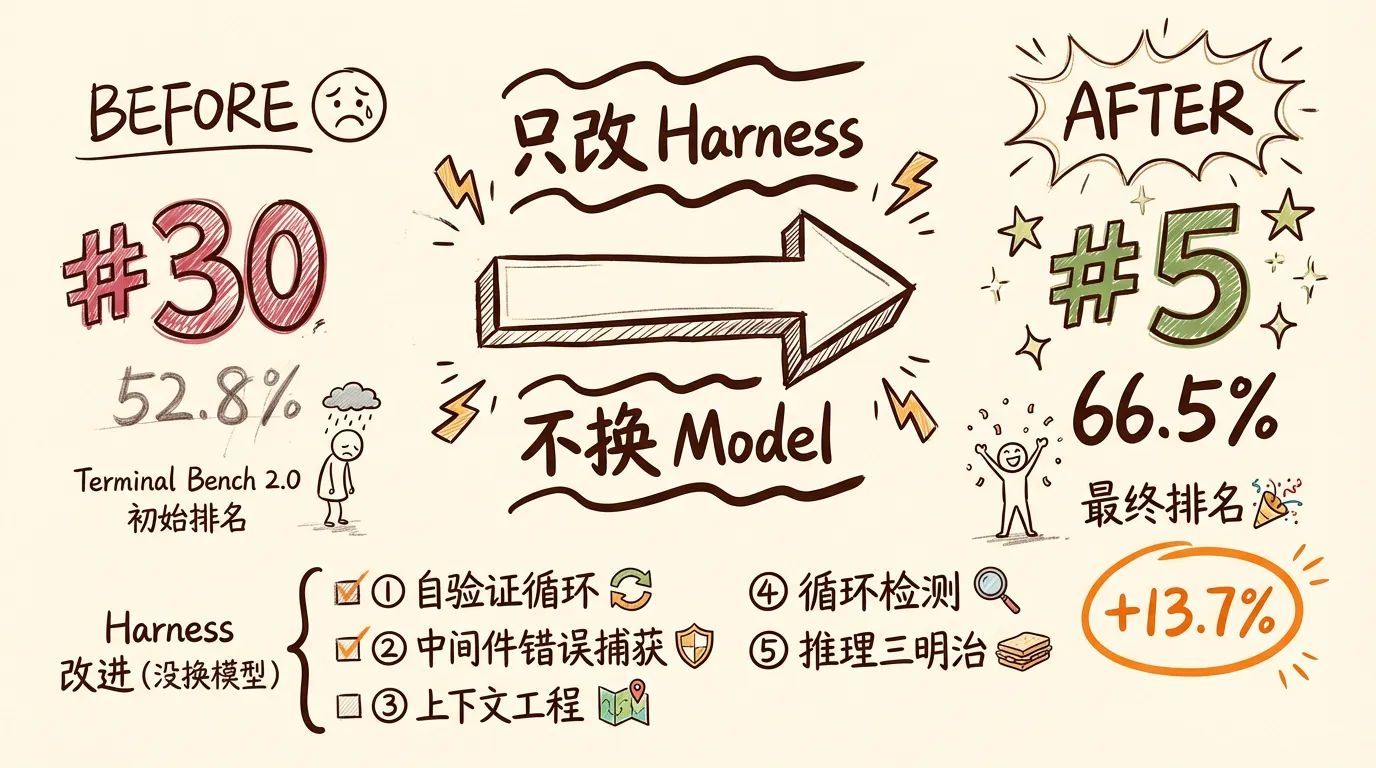
Harness 的反击:从第 30 到第 5
如果上面的公式还是理论,LangChain 自己的经历就是实证。
Terminal Bench 2.0 是另一个编程 Agent 基准测试,侧重评估 Agent 在终端环境中解决复杂任务的能力。LangChain 的编程 Agent 最初在这个榜单上排名第 30。然后他们做了一件事:只改 Harness,不换 Model。成绩从 52.8% 升到 66.5%,排名从 Top 30 跃升到 Top 5。
五项改进,没有一项是"换更好的模型":
- 自验证循环——Agent 改完代码后自动跑测试,不通过就重来
- 中间件错误捕获——工具调用失败时自动重试,不让一次失败中断整个流程
- 上下文工程——启动时映射整个目录结构,让 Agent 先了解项目全貌再动手
- 循环检测——发现 Agent 反复执行相同操作时强制跳出,防死循环
- 推理三明治——在工具调用前后各加一层推理,让 Agent “想清楚再动手”
这不是个例。OpenAI 的 Codex 团队在内部实验中,用 Agent 生成了超过 100 万行代码(据 OpenAI 官方博客披露)。五个月,零人工编写。但这个数字本身不是重点——重点是 Codex 团队反复强调的一个转变:工程师的工作从写代码变成了设计 Harness。100 万行代码的背后,是一个不断迭代的 Harness 系统在驱动 Agent 高效运转。
一句话:模型参数是军备竞赛,Harness 工程才是真正的竞争壁垒。
看不见的代价
到这里你可能觉得:既然 Harness 这么重要,那当前主流工具的 Harness 做得怎么样?
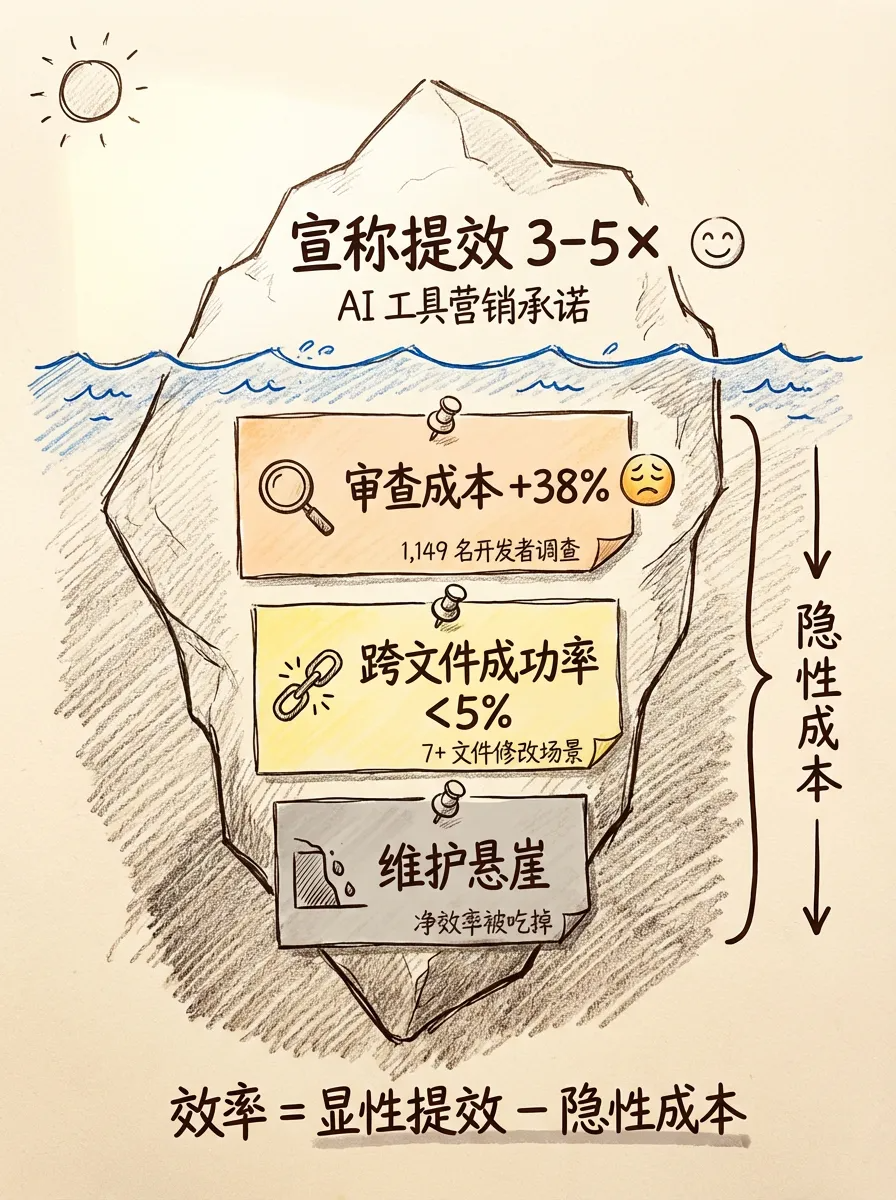
Sonar 在 2025 年底对 1,149 名开发者做了一份调查。数据直接回答了这个问题:38% 的开发者认为审查 AI 生成的代码比审查同事写的代码更费力。这不是"AI 不好用",而是 AI 带来了一种新的隐性成本——你省下的写代码时间,一部分被审查 AI 代码的时间吃掉了。
跨文件修改更能说明问题。SWE-Bench 系列测试中有一项针对移动端场景的子测试(SWE-Bench Mobile,与上文的 SWE-Bench Pro 属于同一基准测试家族,但侧重移动端多文件修改场景),数据显示当修改涉及 7 个以上文件时,Agent 的成功率不足 5%。这意味着 Agent 目前最擅长的是"一个文件内的小修小补",一旦任务需要理解项目全局架构,成功率断崖式下降。
Pragmatic Engineer 的 Gergely Orosz 把这种现象叫做"速度提升的条件性":AI 确实让简单任务变快了,但复杂任务的"快"是表面上的——你把审查、调试、修复 AI 留下的坑的时间算进去,净效率提升远没有宣传的那么高。
这就是标题里"生产力悖论"的含义。工具声称提效 3-5 倍,但隐性成本把一部分提效吃掉了。差距的根源仍然在 Harness:如果 Context Engine 能给模型更准确的上下文、如果反馈循环能在提交前自动捕获问题、如果上下文管理能阻止长任务中的推理退化——这些隐性成本就会大幅降低。换句话说,悖论不是 AI 不行,而是当前的 Harness 还不够好。
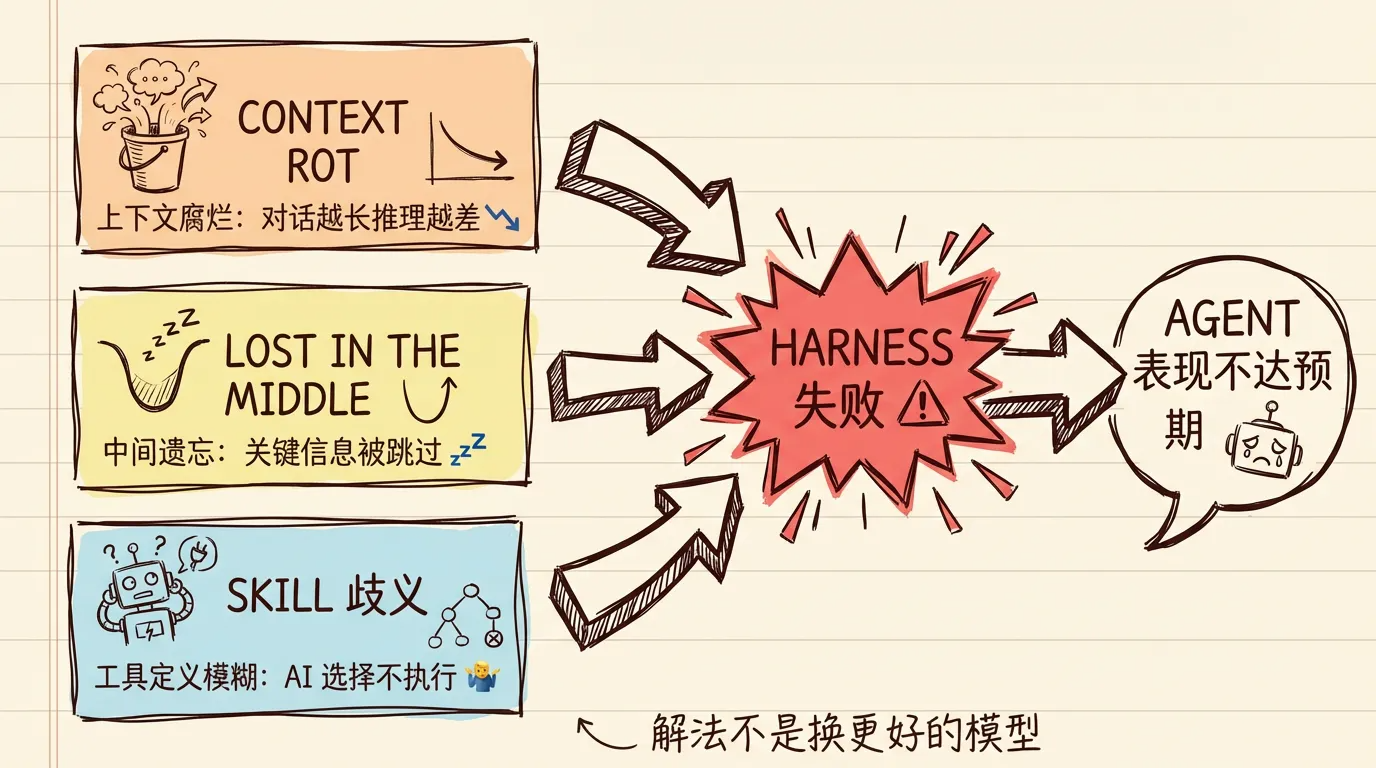
为什么 Harness 失败:上下文的三重问题
Harness 做不好的根因,可以归结为上下文管理的三个技术难题。
第一,Context Rot(上下文腐烂)。 随着对话变长,模型的推理能力下降。LangChain 的研究显示,当上下文膨胀后,模型不是"看不到信息"——而是"信息太多,推理能力被稀释"。这就像你打开了 200 个浏览器标签,每个标签都有用,但你已经记不清哪个标签里有你要找的东西。
第二,Lost in the Middle(中间遗忘)。 Stanford 和 UC Berkeley 的研究发现,语言模型对上下文中间位置的信息注意力显著下降,呈 U 型曲线——开头和结尾的信息被优先处理,中间的信息容易被忽略。这意味着你精心组织的代码库上下文,放在中间的关键信息可能被模型"跳过"。
第三,Skill 歧义(工具定义模糊)。 当 Agent 可用的工具描述不够精确时,AI 不是"不理解"任务,而是面对歧义选择了"不执行"作为安全退路。这是理性行为——就像一个接口契约不清的 API,调用方宁可不调用也不想触发未定义行为。
这三个问题,没有一个靠换更好的模型能解决。它们全是 Harness 层面的工程挑战。
评估工具时,该看什么
回到开头的问题:如果模型不是关键差异,那评估 AI 编程工具时该看什么?
最核心的一个维度是 Context Engine 质量——工具怎么检索和组织代码上下文?有没有语义索引?能不能在你提问之前就理解项目结构?开篇 Auggie 和 Cursor 的 6 个百分点差距,主要来自这里。
Context Engine 的好坏又体现在三个具体能力上。一是上下文管理策略:长任务时怎么处理上下文膨胀?有没有自动摘要压缩?有没有子任务隔离——把复杂任务拆成小任务,每个小任务用独立的上下文窗口,避免 Context Rot。二是工具定义精度:Agent 可调用的工具有多少个?每个工具的描述是否足够清晰?功能重叠会导致 AI 选择困难,这就是前面提到的 Skill 歧义问题。三是反馈循环完整性:Agent 改完代码后会不会自动验证?验证失败后能不能自主修复?LangChain 从 Top 30 到 Top 5 的跃升,第一项改进就是自验证循环。
下次评估 AI 编程工具时,不要问"它用的什么模型"。问"它的 Context Engine 是怎么设计的"。

这是 AI 工程时代三部曲的第一篇。我们从 SWE-Bench Pro 的一组数据出发,拆解了一个基本判断:Agent 的效果差异,根源在 Harness 而非 Model。同一个模型的 6 个百分点差距、仅改 Harness 带来的排名跃升、以及隐藏在提效数字背后的真实成本——三条证据线指向同一个结论。
如果你正在选择或优化 AI 编程工具,关注点从"模型参数"转向"Harness 工程",会是更有效的判断框架。
下一篇,我们聊怎么构建好的 Harness。
参考资料
- Auggie Tops SWE-Bench Pro — Augment Code 官方博客,SWE-Bench Pro 基准测试数据(含 Claude Opus 4.5 声明)
- The Anatomy of an Agent Harness — LangChain 博客,Agent = Model + Harness 框架 + Top 30→Top 5 实证
- Sonar State of Code Developer Survey — 38% 审查成本数据来源(n=1,149)
- Lost in the Middle: How Language Models Use Long Contexts — Stanford/UC Berkeley 研究,U 型注意力曲线(2024 年在 TACL 发表,现象至今仍是活跃研究方向)
- SWE-Bench Mobile — 跨文件修改成功率数据来源(arXiv:2602.09540,2026 年 2 月)
- Pragmatic Engineer Newsletter — AI Coding Agents — Gergely Orosz 关于 AI 编程工具生产力讨论的系列报道(非单篇文章,为付费 Newsletter 持续议题)
- Harness Engineering — OpenAI 官方博客,Codex Agent 内部实验数据(百万行代码实验原始来源)