
TL;DR:Agent Memory 的真正难题不是"怎么存",而是"怎么删"。本文用一次真实的 memory 审计数据,拆解记忆陈腐(Staleness)、冲突和膨胀三类问题,给出 TTL / 冲突覆盖 / 遗忘曲线三种管理策略的适用场景和优先级。
一、事故现场
上周我跟 AI 助手说"我最近在学 Vue 3"。
这没什么问题。但三个月前,我跟同一个助手说过"我们团队用 React,我很熟悉 React 生态"。
后来我问它:“帮我推荐一个状态管理方案。”
它的回答:“考虑到你的技术栈,推荐 Redux(React 生态)或 Pinia(Vue 生态),你可以根据项目选择。”
我盯着屏幕愣了三秒。我已经不用 React 了,它怎么还在推荐 Redux?
答案很简单——它把两条记忆都存了。“喜欢 React"和"在学 Vue 3"在它的记忆库里和平共处,没有任何机制告诉它:这两条信息是冲突的,新的应该覆盖旧的。
这不是个例。我翻了一下自己正在使用的 AI 编程助手 CodeBuddy 的 file-based memory 系统,做了一次冷静的审计。
结果不太好看。
8 个记忆文件,52KB,积累了不到两个月。听起来不多,但问题已经开始冒头了:
- memory 索引说某篇文章"进入锤炼阶段”,实际上它早就发布了——索引自己 stale 了
- 系统在三周前完成了一次术语大迁移(v1 → v2),但有一条记忆还在用旧术语——同一个 memory 系统里,两条记忆对同一件事给出矛盾描述
- 有 3 条"记忆"其实是完整的技术文档(309 行的 API 调用手册——系统自动抽取时未做长度过滤),占了总体积的 57%——记忆变成了垃圾桶
8 个文件就出了这么多问题。想象一下更大规模的 Agent,上百条记忆、数百 KB,如果没有管理机制,memory 系统会从"助手"变成"噪音源"。

二、当记忆开始"溢出"
上面那个 React vs Vue 的例子,问题还算容易发现——两条记忆明显矛盾。但有一种更隐蔽、更危险的情况:记忆没有"错",只是"旧"了。
想象这个场景:
李薇去年 10 月从 B 公司跳槽到 C 公司。她用的 AI 助手记住了大量旧公司的上下文——阿里云部署环境、Java 技术栈。跳槽后她告诉助手"我现在在 C 公司,用 Go + gRPC",助手也记住了。
半年后她问:“帮我写一个服务监控方案。”
助手检索记忆。“阿里云 ECS + K8s"这条记忆相关性很高,确实是部署环境相关的信息。于是它输出了一份基于阿里云 ARMS + SLS 的方案。
问题是:李薇现在在腾讯云上。
这就是 Staleness(记忆陈腐)。高相关但已过时的记忆,和"低相关记忆"不同:低相关的记忆不会被检索命中,不会造成伤害。而 Stale 记忆恰恰相反,它会被优先检索到,而且看起来很合理。这是"自信地给出错误答案”。
这个问题有多普遍?我对那 8 个文件做了有效性评估。
样本量 = 8,仅基于个人审计数据,非行业统计。但趋势清晰:
| 状态 | 占比 | 说明 |
|---|---|---|
| 完全有效 | 25% | 信息准确,当前仍有参考价值 |
| 部分有效 | 62.5% | 核心正确,部分细节过时 |
| 过时 | 12.5% | 已失去存在意义 |
最让我警觉的不是那 12.5% 的"过时",而是 62.5% 的"部分有效"。
“部分有效"比"完全过时"更危险。完全过时的记忆,Agent 有机会发现时间错位,自行忽略。但部分有效的记忆看起来是对的,核心信息也确实是对的。Agent 会因为"大部分正确"而信任整条记忆,顺带接受了那些已经过时的细节。
这正是 Mem0 在 2026 年发布的 State of AI Agent Memory 报告中将 Staleness 列为"开放研究问题"的原因。不是因为它稀有,恰恰是因为目前没有好的解决方案。
还有一个被忽视的问题:记忆只增不减。
43 天,8 个文件,52KB。没有任何自动清理机制,只会越积越多。一条记录了三周前已完成的页面优化任务的记忆,至今仍然安静地躺在记忆库里——不是因为它有用,而是因为没有人(也没有机制)去删除它。
当存储是自动的、免费的,而管理是手动的、昂贵的,记忆系统必然退化。

三、三种"删”
大多数 Agent Memory 教程教你怎么加记忆——怎么嵌入向量、怎么语义检索、怎么连接外部知识库。
很少有人教你怎么删记忆。
这不是疏忽。是因为"删"比"存"难得多。
存储是确定性操作,一条信息要么存了要么没存。删除是不确定性决策,删错了可能比不删更糟。多存了不需要的信息最多浪费空间,删掉了关键记忆可能导致灾难性错误。
但不删不行。前面两章已经说明了为什么。
我把现有的记忆管理策略归纳为三种"删"。它们不是互斥的,是互补的,对应三个不同的维度。
TTL 删除:时间到了就扔
最简单的策略。给每条记忆贴一个保质期,到期自动清理。TTL 简单到只需一个时间戳字段加定时扫描。
适合处理明确有时效的信息:“今天想吃川菜"“用户正在出差"“本次对话的特定需求”。这些记忆天然有过期时间。
但不是所有记忆都有保质期。用户的母校不会过期。编程语言偏好可能几年不变。给这些记忆设 TTL 就像给学历证书贴保质期。
而且 TTL 设多长?短了,有用的记忆被误删;长了,过时的记忆继续污染。不同类别需要不同的 TTL:身份信息(长)≠ 偏好信息(中)≠ 任务信息(短)。
冲突覆盖删:新的替换旧的
当新记忆与旧记忆在语义上冲突时,用新的覆盖旧的。
像手机通讯录,存了朋友的新号码,旧号码自动被覆盖。因为一个人的"当前手机号"只能有一个。
开头那个 React vs Vue 的问题,就该用这个策略解决。“喜欢 React”→“在学 Vue 3”,这是同一维度的偏好变更,新值应该覆盖旧值。
但核心难点在于:什么算"冲突”?
“喜欢 React"和"喜欢 Vue"是冲突吗?如果用户是全栈工程师,同时精通两个框架呢?“我是后端工程师"和"我正在学前端"矛盾吗?当然不——但 Agent 需要理解这一点。
这本质上是自然语言推理问题——判断两条记忆是否在说"同一件事的不同版本”。而且不只是语义:同一条"我喜欢 React”,是指当前项目还是通用偏好?这涉及时间和作用域推理。
真正难的是把这套推理做到工程可靠。不只是字符串匹配,需要语义理解能力。
遗忘曲线淘汰:不用的慢慢忘
如果只按频率淘汰,过敏信息第一个被删——用户可能从没主动提过,但这条记忆可能救命。
这就是按使用频率淘汰记忆的核心矛盾。像图书馆的书架:被频繁借阅的书放在显眼位置,很少被借的书逐渐移到仓库。听起来合理,但有些冷门藏书恰恰是关键时刻唯一的参考。
严格说,这里更接近 LFU(按频率淘汰)而非 Ebbinghaus 遗忘曲线——但"遗忘"这个比喻有助于理解意图,工程实现是另一回事。
用户半年前关注区块链,最近一直聊 AI——区块链记忆权重自然衰减。这很合理。但用户的血型一年被问一次,每次都很关键。调用频率 ≠ 重要性。
一个成熟的遗忘策略需要综合考虑:调用频率、调用质量(检索后是否被采用)、记忆类别(身份 > 偏好 > 任务)、上下文关联度。这是三种策略里最接近人类记忆运作方式的,也是工程上最难落地的。
三种策略的关系:
💡 左侧简单右侧复杂,详见下方对比图。
一个成熟的 Agent Memory 系统应该三者兼备。但现实是:大多数系统连 TTL 都没有做好——它们只有 ADD,没有任何形式的"删”。
除了删,还有"浓缩"。Mem0 和 LangMem 都在做的 memory consolidation——把多条相关记忆合并为一条摘要,减少数量但保留信息。这不是删,是合并。但合并本身也需要判断:哪些记忆算"相关"?合并后丢了哪些细节?又是语义理解问题。
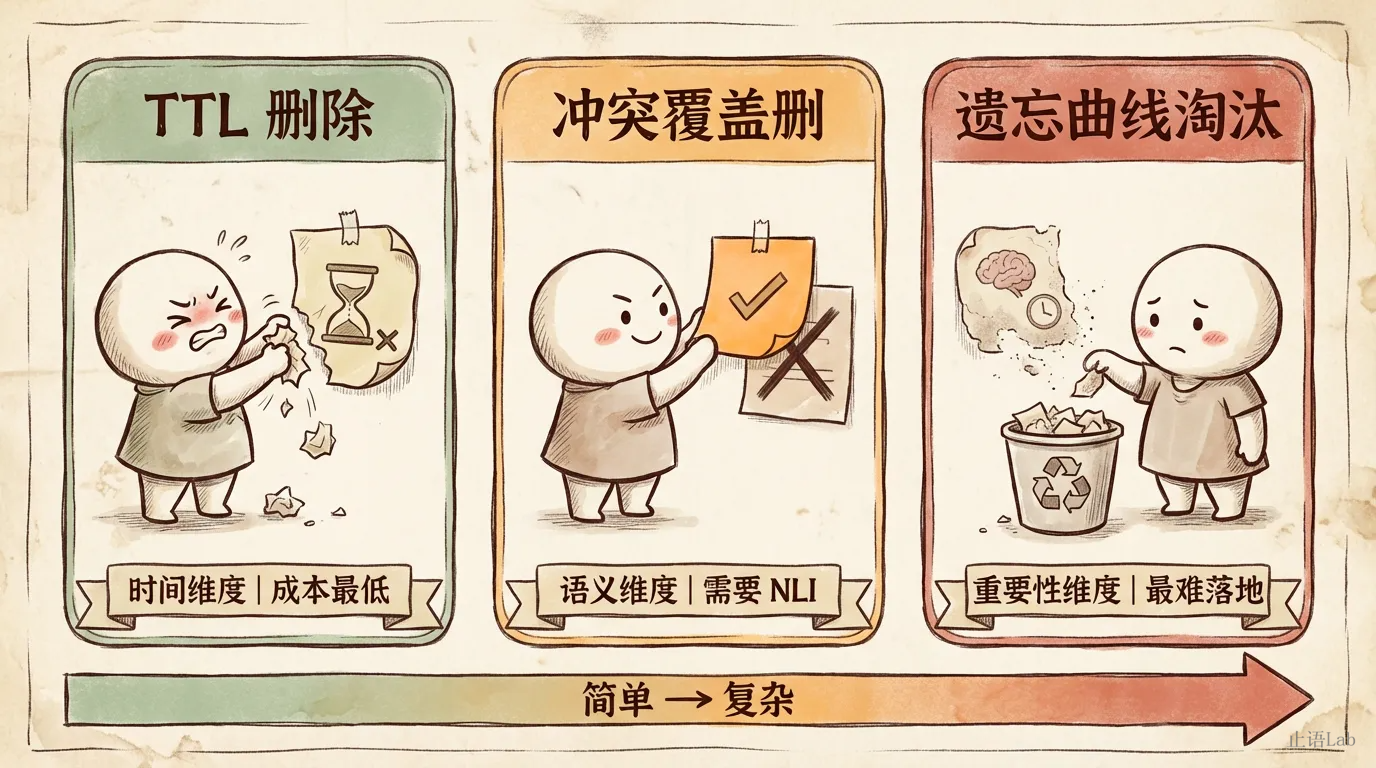
资源有限时,先上 TTL——成本最低、效果最确定。如果用户偏好多变(比如技术栈切换),必须加冲突覆盖。遗忘曲线是锦上添花,前两个做不好之前别碰它。三种策略至少实现一种——先从 TTL 开始,这是成本最低的保险。
四、行业的答案
这不是理论推演——行业头部玩家正在为此争吵。
2026 年初,Mem0 发布了 State of AI Agent Memory 报告。在 LOCOMO 基准测试的加权平均上,选择性记忆 vs 全量上下文,准确率仅差 6%——但注意,在时序敏感任务上差距更大。延迟降低 91%,token 消耗降低 90%。选择存什么、淘汰什么才是瓶颈。
Letta(前 MemGPT)的联合创始人 Sarah Wooders 在社交媒体上公开质疑这组数据。争论背后的根本分歧:Mem0 认为记忆的核心是检索,Letta 认为核心是上下文管理——像操作系统管理虚拟内存。当然这是简化理解——Mem0 也有删除 API,Letta 也需要检索。差异更多在架构哲学:中间件 vs 操作系统。
用我们的框架看,两家不是对立——是三种"删"的不同起点。Mem0 从 TTL 和检索起步(“先能找到”),Letta 从冲突覆盖和状态管理起步(“先别矛盾”)。最终都要走到三者兼备。LOCOMO 基准测试只测"记不记得住",不测"该不该忘记"——而后者才是真正的工程难题。

五、你的 Agent 什么时候需要 Memory
说完了行业,回到你自己。
回到开头那个同时推荐 React 和 Vue 的问题。
真正的答案跟向量数据库和 Embedding 模型都没关系。要从一个更前置的问题开始:你的 Agent 到底需不需要长期记忆?
128K token 的上下文窗口已经能容纳一本小说。但"能装下"不等于"能用好"——研究表明,LLM 对长上下文中间部分的信息检索准确率会显著下降。即便如此,对于大多数单次对话场景——写代码、翻译文档、回答问题——上下文窗口就够了,不需要额外的 Memory 系统。
Memory 系统真正不可替代的场景只有一个:跨会话的个性化。
“用户三个月前说过他偏好 TypeScript”——这条信息不在当前对话上下文里,全量上下文方案(Full-context)做不到。只有持久化的 Memory 才能跨越会话边界。
例外:如果你的 Agent 需要在单次对话中调取用户历史数据(比如客服查工单),仍然需要外部记忆——只是不一定是 Agent Memory,更可能是数据库查询。
如果你的 Agent 只服务单次对话,大概率不需要 Memory。但如果需要跨会话记住用户偏好——那就得上,同时得想清楚怎么管。
如果你决定上 Memory,那这篇文章的核心信息就是你的备忘录:不要只想着怎么存,先想清楚怎么删。
因为记忆溢出不是"内存不够用"。是你的 Agent 记得太多、管得太少,开始自信地给出错误答案。
记忆过期了怎么办——这才是 Agent Memory 的真正难题。
